Delphi vereint mehrere Vorteile in einem Programm. Dabei ist einer der Vorteile, die sofort ins Auge fallen, Delphis unglaublich ausgeklügelte RAD-Umgebung (RAD steht für "Rapid Application Development"). Damit ist es möglich, innerhalb kürzester Zeit das Äußere eines Programmes und auch einige der Abläufe zu erstellen. Das System arbeitet dabei grafisch und als WYSIWYG. Die Entwicklungszeit von Programmen wird durch die sehr ausgereifte Umgebung dabei minimiert.
Ein weiterer Vorteil von Delphi ist seine Sprache. Das frühere Object Pascal, welches inzwischen in Delphi Language umbenannt wurde, ist für Anfänger aufgrund seiner klaren Strukturen und einprägsamen Befehlen sehr leicht zu lernen, bietet Fortgeschrittenen und Profis jedoch eine Vielzahl an Möglichkeiten. Dabei bietet Delphi einen sehr schnellen Compiler an. Delphi Language ist dabei eine Sprache, welche die besten Möglichkeiten zur objektorientierten Programmierung (demnächst kurz: OOP) bietet.
Um nicht nur die vorgegebenen Komponenten zu nutzen, ist es in Delphi möglich, eigene Komponenten zu entwickeln und sie dem Repertoire der vorgegeben Komponeten hinzuzufügen. Aber selbstverständlich ist dies nicht nur mit eigenen Komponenten möglich, sondern Sie können auch die Komponenten anderer Programmierer in Ihre Programme einbinden.
Last but not least bietet Delphi ein sehr gutes Hilfesystem. Dies besteht zum einen aus einer kontextbezogenen Hilfe, die es Ihnen erlaubt, zu jedem Delphibefehl, den sie mit dem Cursor markieren, einen Hilfetext anzuzeigen. Zum anderen bietet Delphi die Möglichkeit, dass während Sie einen Quelltext schreiben, eine Auswahl von zum Objekt gehörigen Methoden und Eigenschaften angezeigt wird.
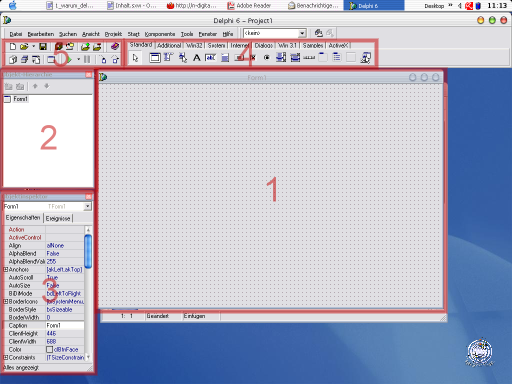
Wenn Sie Delphi (in den Versionen bis Delphi 7) das erste Mal starten, werden Sie ein Bild vor sich sehen, welches in etwa so aussehen sollte. Zwischen den Versionen bis zur Siebten gibt es da nur geringe Unterschiede:
Dies ist die RAD-Umgebung, das Aushängeschild von Delphi, wenn man so will. Was nicht bedeuten soll, dass dies das Wichtigste an Delphi ist, aber es ist auch nicht ganz unwichtig und außerdem das, was die Leute von Delphi wirklich sehen.
Damit Sie einen Eindruck von der Umgebung erhalten, werde ich nun kurz die einzelnen Bereiche ansprechen. Wie man mit diesem Bereich arbeitet, wird jedoch erst im Laufe des Crashkurses deutlich werden. Hier soll nur ein kurzer Überblick gegeben werden.
Um Ihnen zu zeigen, wie schnell Sie – selbst ohne sonderliche Programmierkenntnisse – ein Programm in Delphi gestalten können, werde ich in diesem Abschnitt die Erstellung eines solchen Programmes Schritt für Schritt beschreiben.
Bevor Sie überhaupt daran gehen können, ein Programm in Delphi zu gestalten (und dabei beziehe ich mich vorerst nur auf das Äußere), müssen Sie sich genau überlegen, wie Ihr Programm aufgebaut sein soll. Es geht fast nie gut, wenn man "einfach so drauf los klickt" und ohne sich vorher ein Konzept zurecht gelegt zu haben, die Komponenten auf der Form platziert.
Ein Konzept ist immer programmspezifisch. Will heissen: man muss zuerst die geplanten Funktionen des Programmes kennen und dann ein Konzept entwickeln, welches dem Benutzer diese Funktionen übersichtlich und effektiv präsentiert bzw. zur Verfügung stellt. Dabei gibt es keine festen Regeln, sondern jeder Programmierer entwickelt mit der Zeit seinen eigenen Stil und sammelt auch Erfahrungen durch Feedback von Benutzern oder Kollegen.
Das Programm, welches in diesem Abschnitt erstellt werden soll, ist so einfach, dass es wenig Sinn hat, sich dafür ein Konzept zu überlegen. Es soll lediglich demonstrieren, wie mächtig die RAD-Umgebung von Delphi ist. Erstellt werden soll ein Browser für die Festplatte. Der Nutzer soll den Inhalt aller Verzeichnisse auf seinem Computer anzeigen können.
Zu kompliziert für den Einstieg? Keineswegs! Mit Delphi ist dies in einigen wenigen Schritten erledigt:
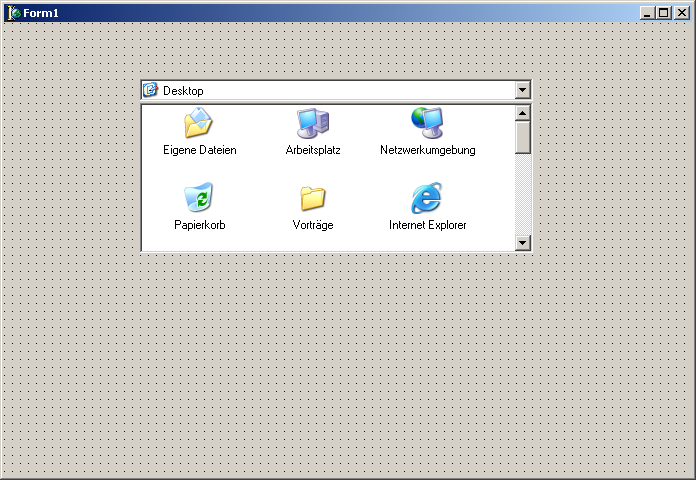
Damit ist das Aussehen des Programmes schon fertig. Und wenn Sie glauben, jetzt würden Sie einen Quelltext schreiben müssen, dann liegen Sie falsch. Dem Nutzer eine Möglichkeit zu bieten, die Dateien des Systems anzuzeigen, ist eine so alltägliche Aufgabe, dass dies in Delphi nicht mehr vom Programmierer erledigt werden muss. Er kann sich auf die wirklichen Herausforderungen konzentrieren.
Das einzige, was nun noch eingestellt werden muss, ist die Verbindung zwischen den beiden Komponenten, damit das in der ShellComboBox ausgewählte Verzeichnis auch in der ShellListView angezeigt wird. Dies ist Dank des Objektinspektors ebenfalls sehr einfach:
Damit ist dieser Abschnitt schon fast fertig. Nun müssen Sie das Programm nur noch ausprobieren. Klicken Sie dafür auf den grünen Pfeil nach rechts, den Sie in der linken Symbolleiste finden. Das Programm startet, und Sie können die Komponenten, wie Sie es aus anderen Programmen gewohnt sind, benutzen. Durch Klick auf den grünen Pfeil wird das Programm kompiliert, also aus dem von Ihnen geschrieben Quelltext ein ausführbares Programm gemacht (eine "normale" EXE-Datei), welche auch außerhalb von Delphi nutzbar ist! Alternativ zum grünen Pfeil können Sie auch die Taste "F9" drücken.
Das Wichtigste in jeder Programmiersprache sind Variablen. Sie versetzen den Programmierer in die Lage, Informationen im Programm abzuspeichern und später wieder abzurufen. Die Quellen für diese Informationen sind dabei vielfältig. Oft werden diese Informationen vom Benutzer (auf einer Vielzahl von Wegen) eingeholt oder aber sie werden (auf verschiedenste Arten) aus bestehenden Informationen gewonnen.
Doch was sind Variablen? Ihr Kontostand ist eine Variable! Eine Variable ist ein Platzhalter, der für einen sich ständig verändernden Wert steht. Ihr Kontostand ändert sich ständig. Und trotzdem wissen Sie genau, welche Zahl ich meine, wenn ich von Ihrem Kontostand rede. In einem Brief, in dem steht "Überweisen Sie mir die Hälfte Ihres aktuellen Kontostandes!" werden Sie an Stelle des Platzhalters "Kontostand" den aktuellen Wert einsetzen.
Genauso arbeiten Variablen. Wenn ich eine Gleichung aufschreibe, wie z.B.
a = b + c
so sind die drei Buchstaben Variablen. Ich kann für "b" den Wert 2 und für "c" den Wert 3 einsetzen und ich erhalte für "a" den Wert 5. Aber ich kann für "b" und "c" genauso gut zwei andere Werte einsetzen. An der Gleichung ändert das nichts. Die drei Buchstaben fungieren als Platzhalter für irgendwelche Werte, es sind Variablen.
In Delphi kann nicht jede Variable jeden beliebigen Wert annehmen. Eine Variable kann zum Beispiel immer nur für eine ganze Zahl stehen oder immer nur für einen Buchstaben. Niemals wird eine Variable für beides stehen können. Delphi ist in dieser Hinsicht sehr strikt und der Programmierer muss bei jeder Variable genau angeben, von welchem Typ sie sein soll. Es muss also vorher festgelegt werden, ob die Varibale für eine Zahl, einen Buchstaben oder ein Datum steht. Und das gilt dann für diese Variable immer.
Daraus resultierend gibt es eine strikte Trennung des Text-Inhaltes eines Edit-Feldes und dem Wert den dieser Text eventuell repräsentiert. Wenn in einem Programm die Aufforderung erscheint, dass der Benutzer seinen aktuellen Kontostand in ein Edit-Feld eingeben soll, dann ist der Inhalt dieses Edit-Feldes erst einmal eine Zeichenkette und keine Zahl. Denn prinzipiell kann ja jedes beliebige Zeichen in ein Edit-Feld eingegeben werden.
Um diesen Text aber als Zahl zu verarbeiten, um also damit zu rechnen, braucht man eine zweite Variable. Denn einen Text kann man nicht multiplizieren und auch sonst keine Rechenoperationen damit durchführen. Man muss also den Wert, den dieser Text repräsentiert, herausfinden und in einer Variable speichern, um damit dann zu rechnen.
Aber um das zu demonstieren, muss man erst einmal ein paar Variablentypen einführen. Grundlegende Aufgaben, die in jedem Programm vorkommen, sind zum einen das Speichern und Verarbeiten von Zahlen und das Speichern und Verarbeiten von Text bzw. Zeichenketten. Und die Variablentypen, die für diese Aufgaben verwendet werden, werden im Folgenden hier vorgestellt.
Wenn in Delphi ein Text gespeichert und verarbeitet werden soll, wird dafür in den allermeisten Fällen der Variablentyp String verwendet. Dies ist eine Aneinanderreihung von bis zu 2^31 Zeichen. Diese Zeichen sind beliebig, es kann sich also um Buchstaben, Zahlen, Leerzeichen oder jedes andere Zeichen, das Sie auf der Tastatur finden (und ein paar mehr) handeln. Sie können auf einen String sowohl als Zeichenkette zugreifen, als auch jedes einzelne Zeichen eines Strings verändern. Wie das geht, wird später noch demonstriert.
Bei Zahlen muss man erst einmal entscheiden, ob man eine ganze Zahl oder eine Zahl mit Nachkommastellen speichern und verarbeiten möchte. Für ersteres verwendet man den Variablentyp Integer und für letzteres den Variablentyp Real. Für beides gibt es je nach Anforderung auch noch andere Datentypen, die beiden genannten sind jedoch sehr gebräuchlich und werden erst einmal ausreichen. Das Speichern von Zahlen ist sehr viel komplizierter als es auf den ersten Blick aussieht, darauf wird jedoch noch später eingegangen.
Um die Verwendung von Variablen und besonders die Verwendung dieser drei Typen deutlich zu machen, eignen sich am Besten ein paar Beispiele. Dazu beginnen Sie ein neues Projekt, dies tun Sie mit "Datei -> Neu -> Anwendung".
Platzieren Sie folgende Komponenten (die Sie alle im Abschnitt "Standard" der Komponentenpalette finden) auf der Form:
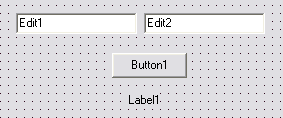
Führen Sie nun einen Doppelklick auf den Button aus. Nun sehen Sie ein Fenster vor sich, in dem Text steht und in dem Sie Text eingeben können. Dies ist der Code-Editor und hier schreiben Sie Ihre Quelltexte. Was es mit dem Doppelklick auf sich hat und mit dem, was Delphi dort schon geschrieben hat, das wird sich später noch klären.
Was dieses Programm tun soll ist Folgendes: zuerst sollen zwei Zahlen ermittelt werden, wobei diese in jeweils einer der beiden Edit-Boxen stehen. Aber sie tun dies natürlich erst einnmal als Text, dieser Text muss dann in die Zahlen umgewandelt werden.
Sind die Zahlen bekannt, so soll die Summe dieser beiden Zahlen berechnet werden und diese in dem Label ausgegegeben werden. Da diese Ausgabe aber wieder ein Text ist, muss die berechnete Summe erst wieder in einen Text umgewandelt werden.
Folgender Quelltext tut dies:
procedure TForm1.Button1Click(Sender: TObject); var zahl1, zahl2, summe : Integer; begin zahl1 := StrToInt(edit1.text); zahl2 := StrToInt(edit2.text); summe := zahl1+zahl2; label1.caption := IntToStr(summe); end;
Bitte beachten Sie, dass die erste, die dritte und die letzte Zeile bereits von Delphi generiert wurden, also nicht von Ihnen eingegeben werden müssen. Nachdem Sie diesen Quelltext in Ihrem Programm haben, wird nun geklärt, was im einzelnen gemacht wird.
Die erste Zeile, welche einer Erklärung bedarf, ist die zweite Zeile. Die erste wurde von Delphi generiert und hat also nichts mit unserem speziellen Problem zu tun. Sie ist allgemeiner und wird später erklärt. Also, die zweite Zeile:
var zahl1, zahl2, summe : Integer;
Hier wird aufgelistet, welche Variablen im restlichen Quelltext verwendet werden. Damit Delphi weiß, dass eine solche Auflistung folgt, wird sie mit dem Schlüsselwort var eingeleitet. Selbst dann, wenn die Auflistung über mehr als eine Zeile gehen sollte, wird das Schlüsselwort nur einmal geschrieben.
Schlüsselwörter sind Wörter, welche in der Programmiersprache an sich bereits eine Bedeutung besitzen. Sie dürfen vom Programmierer im Allgemeinen nicht in anderer Bedeutung verwendet werden. Es gibt ein paar Wörter, die nur in einem bestimmten Kontext Schlüsselwörter sind, welche an anderer Stelle dann auch vom Programmierer verwendet werden dürfen. Schlüsselwörter werden von Delphi fett angezeigt.
Nach dem Schlüsselwort "var" folgen die Namen der Variablen, getrennt durch Kommata. Gleichzeitig muss der Typ der Variablen angegeben werden, dies wird durch einen Doppelpunkt und den Namen des Types gemacht. Jede Anweisung in Delphi wird mit einem Semikolon abgeschlossen, so auch diese Aufzählung.
Noch ein paar Worte zu den Namen von Variablen: Sie sollten die Namen von Variablen immer so wählen, dass Sie genau erkennen können, wozu diese verwendet werden. Dabei sollten Sie sich nicht vor langen Namen scheuen, jedoch können sinnvolle Abkürzungen oft durchaus zu mehr Übersichtlichkeit führen.
Die Möglichkeiten der Namensgebung für Variablen in Delphi sind groß, aber sie sind nicht unbeschränkt. So dürfen Variablennamen beispielsweise nicht mit einer Zahl beginnen, keine Leerzeichen enthalten und auch nicht mit Ausdrücken der Sprache identisch sein. Übrigens sind auch keine Umlaute oder andere Sonderzeichen erlaubt! Diese Einschränkung schließt Delphi 8, aber nicht Delphi 2005 mit ein. Dort gelten andere Regeln, auf die ich hier nicht eingehen möchte.
Nun zu den nächsten beiden Zeilen, von denen ich aber nur eine beschreiben werde, weil die andere praktisch identisch ist:
zahl1 := StrToInt(edit1.text);
Der Doppelpunkt mit einem anschließenden Gleichheitszeichen ist der Zuweisungsoperator in Delphi. Dies sollte nicht mit eine Gleichung verwechselt werden. Nach Anwendung eines Zuweisungsoperators, hat die linke Seite den gleichen Wert wie die rechte Seite. In Worten hieße diese Anweisung also "Nimm das, was auf der rechten Seite steht, und schreibe es in die linke Seite.". Eine Gleichung wäre in Worten eher "Vergleiche die linke und die rechte Seite."
Die linke Seite dieser Zuweisung ist bereits beschrieben worden: es handelt sich um die Integervariable "zahl1", also eine Variable, die nur ganze Zahlen speichert. Doch was ist die rechte Seite? Man kann die rechte Seite mal anders aufschreiben:
STRing TO INTeger (edit1.text);
Dies ist die Umwandlung eines Textes in eine Zahl, die ja schon vorher beschrieben wurde. StrToInt ist eine so genannte Funktion. Wie die genau funktionieren kommt später, hier sei nur gesagt, dass man in eine Funktion Werte hineinsteckt, diese irgendwie verarbeitet werden und die Funktion einen Wert zurückgibt.
Bei StrToInt stecken wir den in Edit1 enthaltenen Text hinein. Diesen erreichen wir über den Befehl "edit1.text" (dazu mehr im Abschnitt über OOP). StrToInt verarbeitet diesen Text und gibt dann einen Integer zurück. Dabei wird die Funktion StrToInt zu einem Platzhalter für ihr Funktionsergebnis, wie eine Variable zum Platzhalter für ihren Wert wird. Am Ende beinhaltet zahl1 den Wert, den der Text in Edit1 repräsentiert.
Mit "zahl2" funktioniert das genauso, es folgt nun also die Zeile mit der Addition. Die braucht wohl nicht ausführlich erklärt werden; die Werte von "zahl1" und "zahl2" werden addiert und der Variable "summe" zugewiesen, also in ihr gespeichert.
Das Ergebnis soll ja in Label1 angezeigt werden. Der in einem Label, welches z.B. den Namen "label1" trägt, enthaltene Text wird über
label1.caption
abgerufen und kann auch darüber (über eine Zuweisung) verändert werden. Dies wird in dieser Zeile gemacht:
label1.caption := IntToStr(summe);
Dabei bedarf die rechte Seite wohl nicht mehr ganz so langer Erklärungen: die Funktion IntToStr macht genau das Gegenteil von StrToInt. In IntToStr stecken wir eine (ganze) Zahl, also einen Integer, hinein und bekommen einen Text, also einen String, heraus. In obiger Zeile wird dieser dann dem Inhalt von Label1 zugewiesen: das Ergebnis der Addition wird in Label1 angezeigt.
Damit ist das Programm aber noch nicht ganz fertig. Es hat noch ein paar Schönheitsfehler. Zum einen sind beim Start des Programmes die beiden Edit-Felder nicht leer, das Label ist sichtbar, selbst wenn noch gar nichts berechnet wurde und der Button trägt die Beschriftung "button1".
Um all dies zu ändern, rufen Sie zuerst wieder die Form1 auf, sodass Sie die Komponenten wieder vor sich sehen. Klicken Sie dann eines der Edit-Felder an. Suchen Sie nun im Objektinspektor nach der Eigenschaft "Text". Diese ist wahrscheinlich schon standardmäßig markiert. Der Wert dieser Eigenschaft (also das, was rechts neben ihrem Namen steht) sollte momemtan "Edit1" sein. Markieren Sie diesen Text und löschen Sie ihn. Gehen Sie genauso bei Edit2 vor. Nun sollten die Edit-Felder beide leer sein.
Beachten Sie, dass Sie gerade nur den Text, der in den beiden Edit-Feldern enthalten ist, geändert haben. Dieser ist völlig unabhängig von ihren Namen. Diese haben sich nicht geändert und sind somit immer noch "Edit1" und "Edit2".
Als nächstes kümmern Sie sich um den Button. Klicken Sie auch ihn an und suchen Sie nach der Eigenschaft "Caption". Dies ist die Beschriftung und auch sie sollte im Objektinspektor standardmäßig ausgewählt sein. Ändern Sie sie in "Addieren". Auch hier bleibt der Name des Buttons unverändert!
Zu guter Letzt muss auch noch der in Label1 enthaltene Text geändert werden, der, wie schon erwähnt, auch hier in "Caption" enthalten ist. Ändern Sie den Text in "keine Summe" oder etwas ähnlich sinnvolles. Nun sollte Ihr Programm fertig sein und Sie können es ausführen.
Ich habe in diesem Abschnitt natürlich vieles nur unzureichend erklärt. Dies ist jedoch nicht anders zu machen, da man einfach nicht alles auf einmal erklären kann, aber vieles, was noch nicht richtig erklärt wurde, für ein laufendes Programm notwendig ist. Man könnte dieses Problem umgehen, indem man bis zum bitteren Ende nur Theorie macht und erst dann anfängt, zu programmieren, aber das würde schnell sehr langweilig werden und Ihnen den Spaß verderben.
Ein weiterer wichtiger Datentyp ist übrigens der Datentyp Boolean, dieser wird im Kapitel "Exkurs - Bool'sche Ausdrücke" näher beleuchtet.
Kontrollstrukturen sind eine der wichtigsten Bestandteile jeder Programmiersprache. Kontrollstrukturen bieten dem Programmierer die Möglichkeit, den Fluss des Programmes zu beeinflussen. Ein Programm kann mittels Kontrollstrukturen gewisse Passagen mehrmals ausführen, ohne dass diese Passagen mehrmals geschrieben werden müssen. Es ist auch möglich, Verzweigungen in ein Programm einzubauen, sodass unter bestimmten Bedingen mal die eine und mal die andere Passage ausgeführt wird.
Bevor man jedoch eine dieser Kontrollstrukturen vorstellen kann, muss man sich erst einmal anschauen, wie man überhaupt eine solche "Passage" definiert, denn das Programm kann ja nicht wissen, welche Programmzeilen man als Einheit betrachtet. Dies macht man mit den Befehlen "begin" und "end".
Zu diesem Zeitpunkt des Crashkurses wird Ihnen die Verwendung von "begin" und "end" wahrscheinlich noch sehr abstrakt vorkommen, da die Kontrollstrukturen, welche auf diese beiden Befehle angewiesen sind, noch nicht klar sind. Aber das sollte kein Problem darstellen, denn die beiden Befehle erklären sich sowieso fast von alleine.
Wenn man ein Programm schreibt, arbeit man oft mit Programmteilen, die man gerne als Einheit betrachten möchte. Dies sieht man z.B. an den Quelltexten, welche Sie für die Button-Klicks geschrieben haben. Dort erscheint erst einmal die Deklaration der Variablen und dann sollen alle nachfolgenden Befehle in einem ausgeführt werden.
Und dort kommen auch schon "begin" und "end" zum Einsatz. Denn mit ihnen macht man dem Programm klar, welche Programmzeilen zu dem Button-Klick gehören. Dies macht man, indem man einen Bereich definiert, in dem sich die zugehörigen Programmzeilen befinden. Den Anfang dieses Bereichs markiert man mit einem "begin" und das Ende dieses Bereichs mit einem "end".
Und so macht man es mit allen Quellcode-Passagen, die man bestimmen will. Anfang und Ende werden mit "begin" und "end" markiert. Dabei sieht der Quelltext so aus:
begin befehl1; befehl2; {...} befehl21; befehl22; end;
Bitte beachten Sie, dass niemals ein Semikolon hinter ein "begin" kommt. Eine so klare Aussage kann man für das Semikolon hinter dem "end" nicht treffen. In den allermeisten Fällen macht man ein Semikolon dahinter, in Ausnahmen jedoch nicht. Auf diese Ausnahmen wird an den jeweiligen Stellen hingewiesen.
Nachdem "begin" und "end" nun klar sein sollten, sollen nun ein paar der wichtigsten Kontrollstrukturen hier vorgestellt werden. Den Anfang macht dabei die Verzweigungen. Diese werden primär mittels einer if-Anweisung realisiert, manchmal auch mit der case-Anweisung.
Zuerst ein bisschen Praxis. Bauen Sie noch einmal ein Programm zusammen, welches dem obigen äußerlich exakt gleicht, tippen Sie jedoch noch keinen Quelltext ein. Der kommt erst gleich. Dieses mal soll nämlich keine Addition der beiden Werte erfolgen, sondern es soll herausgefunden werden, welche der beiden Zahlen die Größere ist.
Dazu müssen zuerst einmal wieder die Zahlen deklariert werden (also die Auflistung nach "var"). Dies können Sie schonmal erledigen, die Summe brauchen wir diesmal nicht. Sie sollten die Variablen dieses mal auch nicht als Integer deklarieren, sondern als Real, denn dieses Mal sollen auch nicht-ganze Zahlen verarbeitet werden. Und auch die Zeilen, um die Zahlen aus den Edit-Felder einzulesen, können Sie schonmal hinschreiben. Der Befehl, den Sie statt StrToInt verwenden sollten, lautet für nicht-ganze Zahlen StrToFloat. Die Verwendung ist die Gleiche.
So, nachdem das erledigt ist, geht es an die Fallunterscheidung. Wie soll diese genau aussehen? So!
Im Grunde genommen soll im Label also das Verhältnis des ersten Wertes zum Zweiten angezeigt werden. Dies kann man so machen:
procedure TForm1.Button1Click(Sender: TObject); var zahl1, zahl2 : Real; begin zahl1 := StrToFloat(edit1.text); zahl2 := StrToFloat(edit2.text); if zahl1 = zahl2 then label1.caption := 'gleich'; if zahl1 < zahl2 then label1.Caption := 'kleiner'; if zahl2 < zahl1 then label1.Caption := 'größer'; end;
Hier können Sie auch gleich mal kontrollieren, ob die Deklaration und das Einlesen der Werte bei Ihnen richtig ist. ;-)
Die ersten Zeilen müssen nicht mehr erklärt werde, da sie im Grunde genommen die selben wie im vorigen Abschnitt sind, mit ganz kleinen Änderungen. Der erste (und einzige) Code-Abschnitt, der erklärt werden solllte, ist folgender:
if zahl1 = zahl2 then label1.caption := 'gleich';
Dies ist eine if-Anweisung. In der momentanen Fassung kann man dabei noch nicht von einer Verzweigung, sondern nur von einer Bedingung sprechen, doch die Verzweigung wird im Laufe dieses Abschnitts noch eingeführt. Um eine if-Anweisung zu verstehen, muss man sich erst einmal mit den so genannten "Bool'schen Ausdrücken" beschäftigen.
Ein Bool'scher Ausdruck ist ein Wahrheitswert (in Delphi durch den Variablentyp "Boolean" vertreten). Er ist entweder "wahr" oder "falsch". Dazwischen gibt es nichts. Die Aussage "Es regnet im Moment!" ist entweder wahr oder falsch. Aber nichts dazwischen. Genauso ist die Aussage "Ich habe genauso viel Geld im Portemonnaie wie Sie!" wahr oder falsch. Nun kann man das Geld in meinem Portemonnaie mit "zahl1" bezeichnen und das in Ihrem mit "zahl2". Dann erhält man aus obiger Aussage die Gleichung: "zahl1 = zahl2".
Bool'sche Ausdrücke sind jedoch nicht immer so einfach. Denn man kann aus zwei Bool'schen Ausdrücken wiederrum einen dritten Bool'schen Ausdruck bilden, indem man die beiden verknüpft. Wie man das macht ist völlig intuitiv verständlich:
procedure TForm1.Button1Click(Sender: TObject); var newBoolean, boolean1, boolean2 : Boolean; begin newBoolean := boolean1 and boolean2; newBoolean := boolean1 or boolean2; newBoolean := not boolean1; newBoolean := boolean1 xor boolean2; end;
Wie man sieht, kann man Bool'sche Ausdrücke über "und", "oder" und "nicht" miteinander verknüpfen. Dies geschieht, wie wir es im Alltag gewohnt sind und muss wohl nicht erklärt werden. Das einzige, was eventuell kurz angerissen werden sollte, ist "xor". Dies steht für "exclusive or", also "ausschließendes oder". Im Alltag nutzt man es durch die Satzkonstruktion "entweder ... oder", was deutlich macht, wie es funktioniert: "newBoolean" ist nur dann wahr, wenn entweder "boolean1" oder "boolean2" wahr sind, aber nicht beide.
Selbstverständlich kann man auch zusammengesetzte Bool'sche Ausdrücke wieder zusammensetzen, oder Konstruktionen mit mehreren Verknüpfungsoperatoren machen. Dabei sollte man jedoch immer darauf achten, dass klar ist, welche Ausdrücke in welcher Reihenfolge verknüpft werden sollen. Zum Beispiel ist folgender Ausdruck missverständlich:
boolean1 and boolean2 or boolean3
Dies wird von Delphi zwar akzeptiert, ist aber für einen menschlichen Leser verwirrend und dem Programmverständnis nicht förderlich. Es sollte daher vermieden werden. Man sollte obigen Ausdruck mit Klammern schreiben, sodass klar ist, welche Verknüpfungen hier gewünscht werden:
(boolean1 and boolean2) or boolean3
Aber wie hätte Delphi diesen Ausdruck ausgewertet, wäre er ohne Klammern geschrieben? Für Delphi ist jeder Ausdruck eindeutig auswertbar, dafür sorgen zwei Regeln: Zum einen ist das die Präzedenz der Operatoren, sozusagen die Stärke der "Bindung" eines Operators. Zum anderen die Reihenfolge der Auswertung, bei Operatoren gleicher Präzedenz. Sie erfolgt von links nach rechts.
Die Präzendenz (oder auch "Rangfolge") von Operatoren mag Ihnen zuerst etwas merkwürdig erscheinen, jedoch kennt sie jeder, der weiß, dass Punkt- vor Strichrechnung geht. Damit wird nämlich genau angegeben, dass die Punktrechnung (also die Operatoren der Multiplikation und Division) eine höhere Präzedenz haben als die Strichrechnung (also die Operatoren der Addition und Subtraktion).
Die Präzedenz der Bool'schen Operatoren ist wie folgt: not, and, or, xor. Bei Operatoren gleicher Präzedenz wird von links nach rechts ausgewertet, ansonsten hat die Präzedenz Vorrang vor der Reihenfolge (wie bei "Punkt vor Strich"). Folgende Schreibweise wäre also äquivalent zu obigem Ausdruck:
boolean3 or boolean1 and boolean2
Die Auswertung von links nach rechts kann man sich beim so genannten Kurzschlussverfahren zu Nutze machen. Dieses wird bei der Auswertung von and- und or-Ausdrücken verwendet. Dabei wird ein solcher Ausdruck von links nach rechts ausgewertet und abgebrochen, sobald das Ergebnis fest steht. Zum Beispiel: Wenn bei einer and-Verknüpfung von zwei Ausdrücken der erste Ausdruck bereits "falsch" ist, so muss auch der Gesamtausdruck "falsch" sein. Der zweite Ausdruck muss gar nicht mehr kontrolliert werden und Delphi lässt das dann auch sein.
Dies ist sehr nützlich, wenn man diese Ausdrücke über eine Funktion bezieht. Dann nähme man als ersten Ausdruck die Funktion, welche besonders schnell ist und als zweiten Ausdruck die Funktion, welche langsamer ist. Der Vorteil: wenn die erste Funktion "falsch" zurückgibt, dann wird die Zweite (langsamere) gar nicht mehr ausgeführt, weil Delphi erkennt, dass dies nicht nötig ist. Bei der vollständigen Auswertung würde dagegen ein Ausdruck auch dann vollständig ausgewertet, selbst wenn sein Ergebnis bereits fest steht. Dies kann auch nützlich sein, zum Beispiel dann, wenn ein Teil des Ausdrucks Auswirkung auf das Programm hat, also z.B. eine Funktion ist, die eine globale Variable ändert. Man redet dann auch von einer Funktion mit Nebeneffekten.
Nun wurde genug über Bool'sche Ausdrücke geredet, jetzt wird noch einmal die if-Anweisung beleuchtet.
Die Struktur der if-Anweisung, die bisher verwendet wurde, kann man also so schreiben:
if {Bool'scher Ausdruck} then {Block1}
"{Block1}" bedeutet, dass dort eine Anweisung stehen kann (wie im obigen Beispiel) oder aber ein kompletter Anweisungsblock, der, wie oben beschrieben, durch ein "begin" und ein "end" beschränkt wird. Dieser Block wird genau dann ausgeführt, wenn der Bool'sche Ausdruck "wahr" ist. Ist er "falsch", wird bei dieser Anweisung nichts ausgeführt.
Dieses Verhalten ist jedoch nicht immer gewünscht. Oft möchte man, dass auch für den Fall, dass der Bool'sche Ausdruck "falsch" ist, eine Anweisung oder ein Block von Anweisungen ausgeführt wird. Und dies wäre dann die Verzweigung, von der ich eingangs geschrieben habe. Dies kann man wohl auch wieder am Besten anhand eines Beispiels erklären:
procedure TForm1.Button1Click(Sender: TObject); var zahl1, zahl2 : Real; begin zahl1 := StrToFloat(edit1.text); zahl2 := StrToFloat(edit2.text); if zahl1 < zahl2 then label1.capion := 'kleiner' else label1.caption := 'größer oder gleich'; end;
Dieser Quelltext ähnelt dem aus dem ersten Teil zu if-Anweisungen, ist von der Funktion her jedoch nicht komplett identisch. Folgendes tut dieser Quelltext: wenn "zahl1" kleiner als "zahl2" ist, so wird dies im Label1 angezeigt, sonst wird in Label1 angezeigt, dass "zahl1" größer oder gleich "zahl2" ist. Und dies ist die gesuchte Verzweigung, da immer nur einer der beiden Befehle ausgeführt wird.
Bitte beachten Sie Folgendes: der letzte Befehl vor einem "else" wird niemals mit einem Semikolon abgeschlossen. Dies gilt auch für den Fall, dass der letzte Befehl das abschließende "end" eines Codeabschnitts ist!
Nun ist der obige Quelltext jedoch nicht äquivalent mit dem vorherigen Quelltext. Er gibt dem Benutzer weniger Informationen, da er nicht zwischen "größer" und "gleich" unterscheiden kann. Dies kann man, wenn man mit else arbeiten will, mit einer verschachtelten if-Anweisung lösen:
if zahl1 < zahl2 then label1.capion := 'kleiner' else if zahl2 < zahl1 then label1.caption := 'größer' else label1.caption := 'gleich';
Hieran sieht man zweierlei: zum einen die oben genannte Verschachtelung und zum anderen, dass die if-Anweisung ab dem "if" bis inklusive zum Block hinter dem "else" als eine Anweisung gilt und sie somit nicht mit "begin" und "end" als Abschnitt gekennzeichnet werden muss. Nicht ganz klar, wie das gemeint ist? Anhand eines Beispiels wird es klarer. Folgendes muss man nicht machen:
if zahl1 < zahl2 then label1.capion := 'kleiner' else begin if zahl2 < zahl1 then label1.caption := 'größer' else label1.caption := 'gleich'; end;
Dies liegt daran, dass folgendes als eine Anweisung verstanden wird:
if zahl2 < zahl1 then label1.caption := 'größer' else label1.caption := 'gleich';
Zusammenfassend kann man die if-Anweisung also so charakterisieren: Die if-Anweisung ist ein Anweisungsgerüst, welches als eine einzige Anweisung betrachtet wird und wie folgt aufgebaut ist.
if {Bool'scher Ausdruck} then {Block1} else {Block2}
Dabei ist die letzte Zeile optional, wird sie jedoch verwendet, so darf der letzte Befehl von "{Block1}" nicht mit einem Semikolon abgeschlossen werden.
Ich habe mich nun sehr lange mit der if-Anweisung und dem drum herum aufgehalten und den ein oder anderen hat inzwischen die Langeweile gepackt. Jedoch ist dies eine der wichtigsten Dinge, die es in Delphi gibt und Sie werden selten ein Programm schreiben, in dem keine if-Anweisung vorkommt. Und damit es dort keine Probleme gibt, bin ich lieber auf Nummer sicher gegangen und war lieber zu ausführlich als zu knapp.
Nun ist jedoch die if-Anweisung nicht die einzige Kontrollstruktur, welche eine Verzweigung des Programmes erlaubt.Es gibt auch noch die so genannte "case-Anweisung". Was versteht man darunter? Wozu braucht man die?
Eigentlich braucht man sie nicht wirklich. Aber sie ist sehr praktisch. Stellen Sie sich vor, Sie lassen den Benutzer eine ganze Zahl zwischen Null und Fünf eingeben. Und je nachdem, welche Zahl eingegeben wurde, möchten Sie eine Aktion ausführen lassen. Dies könnten Sie so lösen:
if zahl = 0 then anweisung1; if zahl = 1 then anweisung2; if zahl = 2 then anweisung3; if zahl = 3 then anweisung4; if zahl = 4 then anweisung5; if zahl = 5 then anweisung6;
Offensichtlich ist dies nicht sehr elegant, es kommt sehr viel Code darin vor, der sich ähnelt und das ist etwas, das einem guten Programmierer die Augen bluten lässt. Eine Lösung bietet eine Case-Anweisung:
case zahl of 0: anweisung1; 1: anweisung2; 2: anweisung3; 3: anweisung4; 4: anweisung5; 5: anweisung6; end;
Dies sieht doch sehr viel besser aus, oder? Man kann es auch noch auf die Spitze treiben und der Case-Anweisung Mengen anstatt nur Zahlen übergeben. Ein Beispiel wie dies geht, folgt auf dem Fuße und zeigt auch die Verwendung eines Else-Zweiges in Case-Anweisungen:
case zahl of 0..3, 5: anweisung1; 4: anweisung2; else anweisung3; end;
Doch alles, was so viele Vorteile besitzt, besitzt meist auch Nachteile. So leider auch die Case-Anweisung:
Übrigens müssen in der case-Anweisung nicht einzelne Anweisungen stehen, sondern man kann auch mehrere durch "begin" und "end" eingeschlossene Anweisungen einfügen.
Schleifen sind extrem wichtige und praktische Kontrollstrukturen einer Programmiersprache. Sie bieten einem Programmierer die Möglichkeit, eine Aktion mehrmals auszuführen, ohne zu der Zeit, zu der er das Programm schreibt, schon zu wissen, wie oft diese Aktion genau ausgeführt werden soll.
Dabei bieten Schleifen verschiedene Möglichkeiten anzugeben, wann die Ausführung der Anweisung gestoppt werden soll, so z.B. neben der Angabe einer Anzahl von Schleifendurchläufen auch eine Bedingung, welche zum Abbruch führt.
Die for-do-Schleife stellt eine Möglichkeit dar, festzulegen, wie oft eine Anweisung ausgeführt wird. Dies wird mit einem so genannten "Zähler" in Form einer "Schleifenvariable" gemacht. Erst einmal ein Beispiel:
for i:=0 to 5 do anweisung;
Hierbei ist "i" eine Variable vom Typ Integer. Die for-do-Schleife macht Folgendes: Zuerst wird "i" der Wert 0 zugeordnet. Dann wird die Anweisung ausgeführt. Dann wird "i" um 1 erhöht, besitzt nun also den Wert 1. Die Anweisung wird wiederrum ausgeführt, usw. Die letzte Ausführung der Anweisung findet statt, wenn "i" den Wert 5 hat. Zu diesem Zeitpunkt wurde die Anweisung sechs Mal ausgeführt. Und zwar für die Werte von "i": 0,1,2,3,4,5.
Dabei ist "i" aber nicht auf die Rolle des Platzhalters zur Angabe der Anzahl beschränkt. Die Wertzuweisung zu "i" macht durchaus Sinn, denn während die Anweisung ausgeführt wird, kann man innerhalb dieser Anweisung (die natürlich wie immer auch aus mehreren Anweisung, welche durch "begin" und "end" eingeschlossen sind, bestehen kann) auf den aktuellen Wert von "i" zugreifen.
var i : Integer; myString : String; begin myString := ''; for i:=0 to 5 do myString := myString + IntToStr(i); end;
Dieser Quellcode macht folgendes: er legt zwei Variablen an, "i" und "myString". Dann wird "myString" auf einen leeren Wert gesetzt. Schließlich kommt die Schleife: in dieser durchläuft "i" die oben bereits genannten Werte. In jedem Schleifendurchlauf wird der aktuelle Wert von "i" in einen String umgewandelt und an "myString" angehängt.
Das Addieren von Strings geschieht dabei ganz intuitiv, sodass die Addition von 'a' und 'b' den String 'ab' ergeben würde. Nach dem die Schleife komplett durchlaufen wurde, wurden also alle Zahlen von 0 bis 5 an einen zu Anfang leeren String angehängt. Also hat "myString" nun den Wert '012345'.
Nachdem das Prinzip der for-do-Schleife nun klar sein sollte, folgen nun noch ein paar Anmerkungen:
Nachdem Sie nun die Schleife kennen gelernt haben, welche den Abbruch über die Anzahl der Schleifendurchläufe regelt, wird nun eine der beiden Schleifen beschrieben, welche den Abbruch an eine Bedingung knüpfen.
Dabei sagte die Übersetzung des Namens bereits, wie die Schleife aufgebaut ist: "wiederhole ... bis". Und dort, wo momentan noch drei Punkte stehen, kommt die Anweisung hin. Und auch hier muss nicht unbedingt eine einzelne Anweisung stehen, sondern es können auch mehrere sein. Aber Sie brauchen kein "begin" und "end". Weshalb das so ist, sehen Sie im nachfolgenden Beispiel.
var i, wert, max : Integer; begin {...} i := 0; wert := 1; repeat i := i + 1; wert := wert * i; until wert >= max; {...} end;
Dieser Quelltext berechnet das "i", mit dem "i!" (i! = i*(i-1)*...*1) größer oder gleich "max" ist. Dabei werden die Befehle, welche zum Schleifenrumpf gehören, bereits durch die Schlüsselwörter "repeat" und "until" begrenzt, "begin" und "end" sind also nicht mehr nötig.
Die Anweisungen werden mindestens einmal ausgeführt, denn die Überprüfung, ob die Bedingung erfüllt ist oder nicht, steht ja am Ende. Die Schleifenbedingung ist ein Bool'scher Ausdruck, wie er bereits besprochen wurde. Sobald dieser Bool'sche Ausdruck wahr ist, wird die Schleife verlassen.
Die while-do-Schleife ("während ... mache ...") ist der repeat-until-Schleife sehr ähnlich und bietet praktisch die gleichen Funktionen. Daher werde ich hier nur auf die Unterschiede eingehen:
Und weil es so schön ist, gibt es auch noch ein Beispiel:
var i, max : Integer; richtig : Boolean; begin {...} i := 2; richtig := true; while richtig do begin i := i*i; richtig := i < max; end; {...} end;
An diesem Beispiel kann man auch noch einnmal die Verwendung von Bool'schen Ausdrücken sehen: "i < max" ist entweder wahr oder falsch und kann deswegen auch einer Variable von Typ Boolean zugewiesen werrden. Damit es keine Verwirrung gibt: der Code hat nichts mit "i!" zutun!
Wie schon während der Beschreibung der case-Anweisung gesagt wurde, sind Codeteile, welchen eine ähnliche oder gar gleiche Funktion besitzen und oft vorkommen, nicht gerne gesehen. Wieso dies so ist, wird nach Einführung der Prozeduren noch einmal besprochen. Jetzt wird erst einmal beschrieben, wie Prozeduren und Funktionen eigentlich funktionieren.
Die Einführung in die Prozeduren hat für Sie den Vorteil, dass es wieder etwas zu programmieren gibt. Das haben Sie übrigens Michael "Luckie" Puff zu verdanken, der mir mit diesem Beispiel aus der Klemme geholfen hat.
Um zu sehen, wie eine Prozedur funktioniert, bauen Sie sich jetzt erst einmal besagtes Beispiel zusammen. Dazu legen Sie ein neues Projekt an und platzieren zwei Labels auf der Form. Der Ort ist eigentlich egal, am besten aber nebeneinander. Schließlich muss noch ein Button platziert und mit "Tauschen" beschriftet werden.
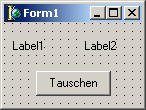
Führen Sie einen Doppelklick auf die Schaltfläche aus, um den Quelltext so einzufügen, dass es hinterher so aussieht wie hier:
procedure TForm1.Button1Click(Sender: TObject); var s1, s2 : String; begin s1 := Label1.Caption; s2 := Label2.Caption; tauschen(s1,s2); Label1.Caption := s1; Label2.Caption := s2; end;
Dabei fällt Ihnen sicher der Befehl "tauschen(s1, s2)" auf. Das ist die Prozedur, die es noch zu schreiben gilt. Sie sieht folgendermaßen aus:
procedure tauschen(var s1, s2 : String); var temp : String; begin temp := s1; s1 := s2; s2 := temp; end;
Diese fügen Sie über den Zeile mit "procedure TForm1...." ein. Starten Sie nun das Programm und betätigen Sie den Button. Achten Sie dabei darauf, was mit der Beschriftung der Labels passiert! Wie Sie sehen, werden die Beschriftungen vertauscht.
Und nun nehmen Sie eine Änderung am Kopf der Prozedur "tauschen" vor. Entfernen Sie das "var" vor "s1, s2 ...". Starten Sie das Projekt erneut und klicken Sie erneut. Sie sehen, was passiert: nichts. Und anhand dieses "Phänomens" wird im Folgenden erklärt, wie eine Prozedur arbeitet.
Dazu werde ich zuerst die Variante beschreiben, die nicht funktioniert. Die ist einfacher. Sie ahnen sicher schon, was eine Prozedur macht: sie fasst Befehle unter einem Namen zusammen. Wenn Sie die Prozedur "tauschen" aufrufen, dann werden die Befehle ausgeführt, die Sie dort festgelegt haben. Die Prozedur ist im Grunde genommen ein kleines Programm für sich.
Aber ein solches Programm wäre sinnlos, wenn es ohne Kontakt zum Rest immer dieselben Befehle ausführen würde. Daher hat man es so eingerichtet, dass man einer Prozedur so genannte Parameter mitgeben kann.
Parameter, das sind die Dinger, die hinter dem Namen der Prozedur in Klammern stehen. Grob gesagt sind es Variablen, welche man beim Starten der Prozedur mit einem bestimmten Wert belegen kann. Dieser Wert ist dann in der Prozedur bekannt und man kann in der Prozedur mit dem Wert arbeiten. Ein Parameter ändert also das Ergebnis und die Aktionen einer Prozedur: anderer Wert, andere Aktion.
Was passiert nun in der Prozedur mit den Parametern s1 und s2? Sie werden getauscht. Ein solcher Tausch wird Ihnen während Ihrer Programmierertätigkeit sehr oft begegnen. Um den Wert zweier Variablen zu tauschen, braucht man immer eine Dritte. Anstatt dass ich dies nun mit vielen Worten beschreiben, sollten Sie sich einfach die Grafik ansehen.
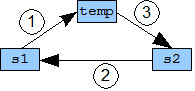
Somit ist nun klar, was beim Aufruf von "tausche(s1, s2)" passiert. Und da Sie vorher den Inhalt von Label1 in die Variable "s1" geschrieben haben und den Inhalt von Label2 in die Variable "s2", und nach dem Aufruf von "tausche" das Ganze umgekehrt machen, sollten der Inhalt der Labels hinterher ebenfalls getauscht sein. Man beachte: "s1" gehört immer zu Label1 und "s2" gehört immer zu Label2. Wieso geschieht dies nicht?
Dies liegt, wie Sie sicher schon vermuten, an dem Zusatzwort "var", welches ja zuerst vor den Parametern stand und das Sie entfernt hatten. Ohne dieses Schlüsselwort, wird in der Prozedur nicht mit den übergebenen Variablen selbst gearbeitet, sondern mit einer Kopie dieser Variablen. Dinge, die mit den Variablen in der Prozedur angestellt werden, haben also keine Auswirkung auf die Variablen im aufrufenden Programm. Diese Methode des Aufrufs nennt man "Call by Value", weil mit dem Wert der Variable, aber nicht mit der Variable selbst gearbeitet wird.
Wenn Sie das Schlüsselwort "var" hinzufügen, wird die Aufrufmethode geändert. Die Prozedur wird nun mittels "Call by Reference" aufgerufen. Das heißt, nun wird nicht mehr nur mit dem Wert der übergebenenen Variable gearbeitet, sondern mit der Variable selbst. Es wird also eine Referenz auf die Variable als Parameter übergeben, also sozusagen ein "mit der da musst Du arbeiten".
Und deswegen wird bei der Methode mit "Call by Reference" auch die Beschriftung der Labels geändert, weil nämlich in der Prozedur mit den Variablen gearbeitet wird, die beim Button-Klick definiert wurden und nicht mit einer Kopie derselbigen.
Funktionen unterscheiden sich im Prinzip nur darin von Prozeduren, dass Funktionen einen Wert zurückliefern, also ein Ergebnis haben. Folgender Quelltext soll als Beispiel heran gezogen werden, welches zeigen soll, wie man Funktionen nutzt. Dabei wird das selbe Ergebnis einmal mit und einmal ohne Funktion realisiert. Zuest einnmal ohne eine Funktion:
var a, b, c, erg1, erg2, erg3: Integer; begin erg1 := a*a*a*a + a*a*a + a*a + a; erg2 := b*b*b*b + b*b*b + b*b + b; erg3 := c*c*c*c + c*c*c + c*c + c; erg1 := erg1*erg1*erg1*erg1 + erg1*erg1*erg1 + erg1*erg1 + erg1; erg2 := erg2*erg2*erg2*erg2 + erg2*erg2*erg2 + erg2*erg2 + erg2; erg3 := erg3*erg3*erg3*erg3 + erg3*erg3*erg3 + erg3*erg3 + erg3; end;
Und dann einmal mit Funktion:
function rechnen (wert : Integer) : Integer; begin result := wert*wert*wert*wert + wert*wert*wert + wert*wert + wert; end; procedure TForm1.Button1Click(Sender: TObject); var a, b, c, erg1, erg2, erg3: Integer; begin erg1 := rechnen(a); erg2 := rechnen(b); erg3 := rechnen(c); erg1 := rechnen(erg1); erg2 := rechnen(erg2); erg3 := rechnen(erg3); end;
Nun wird klarer, wie eine Funktion funktioniert. Die Funktion in diesem Beispiel heißt natürlich "rechnen", was nicht sonderlich kreativ ist, aber für ein Beispiel ausreicht. Wie funktioniert nun aber diese Funktion?
Wenn man eine Funktion schreibt, gibt man zuerst einnmal an, dass es sich überhaupt um eine Funktion handelt. Dies macht man mit dem Wort "function". Dann bestimmt man den Namen der Funktion. Und schließlich muss man noch angeben, welche Parameter eine solche Funktion hat.
Auch muss man angeben, was für einen Typ die Funktion zurückgibt, also welchen Typ das Ergebnis hat. Kommt am Ende ein String heraus, oder vielleicht doch ein Integer? Diesen Typ gibt man nach den Parametern an und zwar so, als wäre die Funktion eine Variable: man trennt den Rückgabetyp mit einem Doppelpunkt vom Rest und gibt dann den Typ an.
Um auf das oben genannte Beispiel zurückzukommen: der Name ist "rechnen", der einzige Parameter ist "wert" und ist vom Typ "Integer", es wird ein Integer zurückgegeben. Der Parameter wird entsprechend der Formel mit sich selbst multipliziert (und ein bisschen addiert) und schließlich dem Ergebnis zugewiesen. Das Ergebnis verwendet man in der Funktion selbst wie eine Variable, sein Name als solche ist "result". Eine Deklaration ist nicht erforderlich.
Im Hauptprogramm, welches die Funktion aufruft, kann man die Funktion fast so benutzen wie eine Variable desselben Typs. Man kann ihr natürlich keine Werte zuweisen. Außerdem sollte man sich im klaren darüber sein, dass eine Funktion jedesmal, wenn man sie in einer Formel benutzt, erneut aufgerufen wird. Ein Aufruf folgender Art macht dann wenig Sinn:
var ergebnis, a : Integer; begin ergebnis := rechnen(a)*rechnen(a)*rechnen(a); end;
Es würde dreimal hintereinander dieselbe Funktion mit demselben Parameter ausgeführt werden, was Rechenzeit kostet. Sinnvoller ist dieser Quelltext, bei dem das Ergebnis nur einmal ausgerechnet wird und dann in einer temporären Variable gespeichert wird.
var temp, ergebnis, a : Integer; begin temp:=rechnen(a); ergebnis := temp*temp*temp; end;
Besonders beim letzten Beispiel wird klar geworden sein, weshalb eine Funktion Sinn macht: sie spart Arbeit. Aber das ist natürlich nicht alles, deswegen hier noch einmal eine Aufstellung der Vorteile von Funktionen und Prozeduren:
Ich hoffe, durch diese Aufstellung ist klarer geworden, was Prozeduren und Funktionen zu einem unheimlich mächtigen Werkzeug macht. Und ebenso hoffe ich, dass Sie zu Ihrem und dem Wohl der Leute, die einmal ihren Quelltext lesen werden, reichlich gebrauch davon machen.
Ein Array ist in praktisch jeder Programmiersprache eine wichtige Möglichkeit, Daten strukturiert abzulegen. Ein Array besteht aus beliebig vielen Elementen. Diese Elemente besitzen alle eine eindeutige "Adresse" in diesem Array, welche ein Tupel aus n Zahlen ist. Dabei ist n die Dimension des Arrays.
Mit dieser Information kann man sich ein Array natürlich noch nicht wirklich vorstellen. Daher möchte ich hier ein paar einfache Beispiel nennen. Zuerst die einfachste Variante, das eindimensionale Array: das kann man sich vorstellen, wie eine Tabelle mit nur einer Spalte:
Wert [1]
Wert [2]
Wert [3]
Wert [4]
So sähe ein eindimensionales Array aus. Jedem Element ist genau eine Zahl zugeordnet, also ein Tupel aus nur einer Zahl. Ein zweidimensionales Array kann man sich auch noch gut vorstellen. Das ist einfach eine Tabelle mit Zeilen und Spalten:
Wert [1,1] Wert [1,2] Wert [1,3]
Wert [2,1] Wert [2,2] Wert [2,3]
Wert [3,1] Wert [3,2] Wert [3,3]
Für dieses Array benötigt man bereits ein Paar von Zahlen, um einen Wert eindeutig zu identifizieren. Man sieht leicht, dass die Anzahl der Elemente, die ein Array enthält, unabhängig von der Dimension ist. Man könnte in obiger "Tabelle" beliebig viele Spalten und Zeilen hinzufügen und sie bliebe immer noch zweidimensional. Die Dimension eines Array gibt einfach nur an, wieviel Zahlen ich brauche, um ein Element eindeutig zu identifizieren.
Die Elemente eines Arrays spricht man an, indem man zuerst den Namen des Arrays schreibt und dann in eckigen Klammern dahinter das Zahlentupel, welches dem Element entspricht. Dabei werden die Zahlen durch Kommata getrennt. Im Prinzip also so, wie es schon in obigen Beispielen getan wurde, nur dass man die Leerzeichen weglässt.
In Delphi unterscheiden sich Arrays nicht nur nach ihrer Dimension, sondern auch danach, ob sie "statisch" oder "dynamisch" sind. Bei einem statischen Array sind sowohl Dimension als auch die Anzahl der Elemente von Anfang an bekannt und können während des Programmablaufs nicht mehr geändert werden. Dynamische Arrays sind dagegen in der Lage, ihre Größe (aber nicht ihre Dimension) zu ändern.
Wenn man von einem zweidimensionalen Array ausgeht, muss ich bei einem statischen Array vorher festlegen, wieviele Zeilen und Spalten dieses Array hat. Bei einem dynamischen Array muss ich nur festlegen, dass das Array Zeilen und Spalten besitzt. Die Anzahl der Zeilen und Spalten (also die Größe des Arrays) ist veränderbar: dynamisch.
Ich möchte im folgenden zuerst die Verwendung von dynamischen Arrays demonstrieren und hinterher nur noch kurz die Unterschiede zwischen der Verwendung von dynamischen und statischen Arrays aufzeigen.
Um ein dynamisches Array zu benutzen, muss man es, wie jede andere Variable auch, erst einmal deklarieren. Die Deklaration eines Arrays besteht aus der Angabe, dass es sich überhaupt um ein Array handelt und aus der Angabe, von welchem Typ die Elemente sind. Dabei ist als Typ der Elemente jeder Datentyp erlaubt. Die Deklaration eines dynamischen, eindimensionalen Integer-Array sieht dann so aus:
var myIntArray : Array of Integer;
Ein mehrdimensionales Array wird ähnlich deklariert. Jedoch deklariert man es so, dass man z.B. für ein zweidimensionales Array ein Array in einem Array deklariert. Die Deklaration sieht dann so aus:
var my2DIntArray : Array of Array of Integer;
Wie muss man sich das vorstellen? Um das zu klären, möchte ich noch einmal das "tabellenartige" Array von oben herauskramen. Dies lässt sich auch so schreiben:
Array [1] | Array [1] = Wert [1] Wert [2] Wert [3]
Array [2] | Array [2] = Wert [1] Wert [2] Wert [3]
Array [3] | Array [3] = Wert [1] Wert [2] Wert [3]
Also ist ein zweidimensionales Array nichts anderes, als ein eindimensionales Array, welches als Elemente wieder Arrays hat. Der Datentyp der Elemente ist ganz einfach "Array of ...".
Damit wäre das Array auch schon deklariert. Mehr ist nicht nötig. Bei statischen Arrays geht es etwas anders, aber darauf gehe ich, wie gesagt, später noch ein.
Um ein dynamisches Array zu benutzen, muss man erst einmal die Größe festlegen, welche zu Anfang in jeder Dimension Null ist. Die Größe eines solchen Arrays legt man mit dem Befehl SetLength fest. Als Parameter übergibt man der Prozedur als erstes den Namen des Arrays, dessen Größe geändert werden soll und als zweites die neue Länge des Arrays:
SetLength(myIntArray, 2);
Mit diesem Quelltext setzt man die Länge des Arrays "myIntArray" auf zwei, das heißt, es hat zwei Elemente. Wichtig: die Indizierung eines dynamischen Arrays beginnt immer bei Null! Das heißt, die Elemente des obigen Arrays haben die Nummern 0 und 1.
Um mit einem zweidimensionalen, dynamischen Array zu arbeiten, muss man dessen Größe in beiden Dimensionen festlegen, da die Größe zu Anfang in beiden Dimensionen Null ist. Dies geht ganz analog zum Vorgehen bei nur einer Dimension, wenn man sich erinnert, wie dieses aufgebaut ist.
SetLength(my2DIntArray, 3); SetLength(my2DIntArray[0], 1); SetLength(my2DIntArray[1], 5); SetLength(my2DIntArray[2], 7);
Dieser Quelltext setzt in der ersten Zeile die Größe in der obersten Ebene des Arrays (die linke Seite bei der Darstellung des 2D-Arrays von oben) auf drei und setzt dann die Größe der drei Elemente dieser Ebene, also den dynamischen Arrays, die in my2DIntArray enthalten sind (die rechte Seite bei der Darstellung des 2D-Arrays von oben). Jedoch wird hier kein "rechteckiges" Array erstellt, sondern die einzelnen Zeilen sind nicht gleich lang.
Das mit diesem Quelltext erstellte Array sieht so aus:
x
x x x x x
x x x x x x x
Möchte man ein rechteckiges Array haben, so gibt es eine sehr praktische Überladung der Prozedur "SetLength". Sie erhält ein Argument mehr, nämlich die Länge der "untergeordneten" Arrays. Folgender Quelltext erstellt ein "rechteckiges" Array mit zehn Zeilen und zehn Spalten:
SetLength(mySecond2DIntArray, 10, 10);
Da bei einem dynamischen Array die Größe eine Variable ist, muss es, damit man vernünftig damit arbeiten kann, eine Möglichkeit geben, die Größe herauszufinden. Dafür bietet Delphi zwei Funktionen. "Length" und "High", wobei "Length" die Größe des Arrays ist und "High" der höchste, zulässige Index. Bei einem dynamischen Arrys ist "Length" also immer um eines Größer als "High".
High(my2DIntArray);
Dieser Aufruf liefert 2 zurück, denn das Array enthält ja drei Zeilen! Ein Aufruf von "Length" würde 3 zurück geben. Um den höchsten zulässigen Index der "Unterarrays" herauszufinden, wendet man High einfach auf sie an:
High(my2DIntArray[0]);
liefert 0 zurück (weil es ja nur ein Element enthält) und
High(my2DIntArray[3]);
liefert 6 zurück. "Length" würde 1 bzw. 7 zurückliefern.
Ein Array zu kopieren ist nicht so trivial, wie dies bei einer Variable ist. Bei einer Variable könnte man diese einfach einer anderen zuweisen. Bei einem Array funktioniert eine solche Zuweisung nicht! Eine Zuweisung wie diese
array1 := array2;
hätte ganz einfach den Effekt, dass nun "array1" ein Synonym für "array2" ist, dass heißt, dass "array1" und "array2" das selbe Array nur mit einem anderen Namen sind. "array1" ist dann eine Referenz auf "array2". Erinnern Sie sich an "call by reference"!
Aber natürlich gibt es eine Möglichkeit, auch ein Array zu kopieren und zwar mit der Funktion "copy". Diese erhält wahlweise einen oder drei Parameter. In der ersten Variante ist der einzige Parameter das zu kopierende Array, bei der zweiten Variante wird angegeben ab welchem Index wie viele Elemente kopiert werden sollen. Zwei Beispiele machen das deutlicher:
array1 := Copy(array2); //kopiert array2 komplett in array1 array1 := Copy(array2, 3, 4); //kopiert 4 Elemente beginnend mit Index 3
Aber Vorsicht: wenn ein Array einen Refernzdatentyp enthält, müssen die Elemente einzeln kopiert werden, dann erstellt auch Copy nur ein Array, welches Referenzen auf die selben Objekte enthält.
Die Deklaration von statischen Arrays ist nicht viel schwerer als die Deklaration von dynamischen Arrays. Man muss jedoch bei statischen Arrays die Größe mit angeben. Außerdem kann man auch den kleinsten Index angeben, dieser muss also nicht unbedingt 0 sein. Den kleinesten Index eines Arrays erhalten Sie übrigens über die Funktion "Low".
my2DIntArray : Array[5..17, 9..20] of Integer; my2DIntArray : Array[5..17] of Array[9..20] of Integer;
Beide Deklarationen ergeben das selbe Array. Eine Aufruf von "SetLength" ist weder nötig noch möglich.
Bei statischen Arrays gibt es eine gute und ein schlechte Nachricht. Die Schlechte wie immer
zuerst: der Copy-Befehl funktioniert nicht. Man muss also im Allgemeinen jedes Element einzeln
kopieren. Und nun die Gute: manchmal braucht man das doch nicht. Denn dann, wenn das Arrays
ausschließlich primitve Datentypen enthält (also Boolean, Integer, Char, ...), erzeugt eine
einfache Zuweisung bei einem statischen Array eine Kopie des Arrays und nicht nur eine Referenz!
Die Benutzung von Variablen wurde ja schon besprochen und auch angewendet. Jedoch war das noch nicht alles. Bei einer so wichtigen Einrichtung wie Variablen muss noch ein wenig mehr beschrieben werden. So gibt es verschiedene Möglichkeiten, Variablen zu deklarieren. Ebenfalls wichtig und noch nicht besprochen ist die Speicherung von Zahlen. Diese zu kennen ist wichtiger, als man zuerst denken mag.
Wir haben bereits Prozeduren und Funktionen kennen gelernt. Auch in diesen kann man Variablen deklarieren. Diese dort deklarierten Variablen nennt man "lokal deklariert". Sie gelten nur in dieser Prozedur bzw. Funktion (ich werde demnächst nur noch von Prozeduren sprechen, wenn nichts anderes gesagt wird, ist das Gesagte auch auf Funktionen anzuwenden!). Sobald das Programm diese Prozedur verlassen hat, gibt es die Variablen nicht mehr und sie sind nicht mehr bekannt. Auch ihren Wert verlieren sie. Dieser Wert taucht auch nicht mehr auf, wenn die Methode erneut aufgerufen wird. Ihr Wert ist dann wieder undefiniert.
Hier ein Beispiel:
procedure myProz; var i,a : Integer; begin for i:=0 to 10 do a:=a+1; end;
Hier sind sowohl die Variable "i" und die Variable "a" nur lokal definiert. Sie sind also außerhalb dieser Prozedur nicht bekannt und man kann auf sie nicht zugreifen. Noch dazu ist der Wert der Variable a nicht definiert, da sie deklariert wurde, ihr aber vor Schleifeneintritt kein Wert zugewiesen wurde. Der Delphi-Compiler wird Sie jedoch darauf hinweisen.
Wenn Sie diese Prozedur nun zweimal hintereinander aufrufen, so hat a beim zweiten Durchlauf keinesfalls den Wert, den es nach dem ersten Durchlauf hatte. Der Wert ist wieder undefiniert, so als hätte es den ersten Aufruf der Prozedur nie gegeben.
Sie haben aber auch die Möglichkeit, Variablen so zu deklarieren, dass diese in jeder Prozedur der Datei sichtbar und verwendbar ist. Diese global deklarierten Variablen verlieren ihren Wert niemals. Um eine solche Variable zu deklarieren, tun Sie dies außerhalb jeder Prozedur entweder direkt vor oder direkt nach dem Wort implementation. Die Position der Deklaration hat ebenfalls eine Bedeutung, auf die ich jedoch später eingehen werde.
Die Deklaration erfolgt genau wie die Deklaration innerhalb einer Prozedur. Einfach mit dem Schlüsselwort "var" einleiten und dann die Deklaration wie gehabt. Sie sollten jedoch dreimal überlegen und dann noch einmal, bevor Sie eine Variable global deklarieren. Denn dies widerspricht dem Prinzip der objektorientierten Programmierung, auf welche ich im nächsten Kapitel noch eingehen werde.
Sollten Sie nach reiflicher Überlegung immer noch zu dem Schluss kommen, dass Sie eine Variable global deklarieren möchten, dann achten Sie darauf, dass Sie einen Namen wählen, der nicht mit einer lokalen Deklaration identsich und gut unterscheidbar ist. Für Delphi ist das zwar kein Problem, aber es beugt Missverständinssen auf Seiten des Programmierers vor. Sollten eine lokale und eine globale Variable aber doch einmal den gleichen Namen haben, so wird – falls man sich in der Prozedur mit der lokalen Variable befindet – die lokale Variable verwendet.
Die Deklaration einer globalen Variable unterscheidet sich in einer Möglichkeit von der Deklaration einer lokalen Variable. Und zwar kann man einer globalen Variable direkt bei der Deklaration einen Wert zuweisen, einen Initialwert. Dies tut man folgendermaßen (als Beispiel):
var myVar : Integer = 5;
Äußerst wichtig aber leider kaum beachtet ist die Zahlendarstellung im Rechner. Um zu verstehen, wie die Darstellung im Rechner funktioniert, muss man sich erst noch einmal klar machen, wie die "richtige" Zahlendarstellung funktioniert. Nehmen wir als Beispiel die Zahl 1234.
Die Zahl ist
4 mal 1 = 4*100 plus 3 mal 10 = 3*101 plus 2 mal 100 = 2*102 plus 1 mal 1000 = 1*103
Dabei nennt man die 10 in diesem Beispiel die "Basis" des Zahlensystems. Aus diesem Grund heißt unser Zahlensystem auch das "Dezimal"system. Die Zahl vor der 10 kann aus einem Bereich von 0 bis 9 stammen. Die Potenz an der Zehn kann eine beliebige ganze Zahl sein (für ganze Zahlen).
Eine Darstellung zur Basis 10 ist in einem Computer jedoch nicht praktisch. Als viel praktischer erweist sich die Darstellung zur Basis 2, auch das "Binär"system genannt. Der Computer kennt in seinem Innersten nur zwei Zustände, "an" und "aus". Oder auch "kein Strom" oder "Strom". In der Informatik: Null oder Eins. Und weil dies genau zwei Zustände sind, ist eine Zahlendarstellung zur Basis 2 bei einem Computer viel besser als zur Basis 10.
Die Darstellung funktioniert genauso wie die Darstellung zur Basis 10, nur dass man diese Darstellung nicht gewohnt ist und man daher etwas länger braucht, um sich zu überlegen, wie sich eine Zahl zusammensetzt. Als Beispiel (auf Grund der Schwierigkeiten dabei auch etwas kürzer ;-)):
12 =
0 mal 1 = 0*20
plus 0 mal 2 = 0*21
plus 1 mal 4 = 1*22
plus 1 mal 8 = 1*23
= (1100)2
Dabei bedeutet die Zahl in Klammern mit dem Index 2, dass man die Zahl zur Basis 2 darstellt. Man lässt diese Schreibweise weg, wenn die Zahl im Dezimalsystem dargestellt wird. Die Basis wird immer in Dezimaldarstellung angegeben.
Ebenfalls wichtig im Bereich des Computers ist das Hexadezimalsystem, also die Schreibweise zur Basis 16. Da wir aber nur zehn arabische Ziffern kennen, benutzt man für die Ziffern 10, 11, 12, 13, 14, 15 (und im Hexadezimalsystem sind die Ziffern) die Buchstaben von A bis F. Die Zahlen von 0 bis 15 lauten im Hexadezimalsysten dann:
0,1,...,A,B,C,D,E,F
Die Darstellung im Hexadezimalsystem wir sehr gerne im Bereich der Farbangaben verwendet. Um für jede Grundfarbe (Rot, Grün, Blau) eine Abstufung von 255 Schritten zu erreichen (und damit ca. 1,6 Millionen verschiedene Farben), bräuchte man normalerweise (also im Dezimalsystem) neun Stellen. Für jede Farbe drei.
Schreibt man eine solche Farbangabe jedoch im Hexadezimalsystem, so benötigt man nur noch sechs Stellen, da gilt:
255 = (FF)16
Bisher wurde nur beschrieben, wie man ganze Zahlen darstellen kann. Nun braucht man in genauso vielen Fällen aber rationale Zahlen, sprich "Kommazahlen". Nur eine (wenn auch große) Teilmenge davon ist im Rechner darstellbar: die rationalen Zahlen, also Zahlen, die sich als Bruch darstellen lassen.
Prinzipiell wäre es möglich, rationale Zahlen analog zu den ganzen Zahlen darzustellen, indem man die Potenzen an der Basis einfach in den negativen Bereich erweitert. Als Beispiel:
23 + 21 + 20 + 2-1 + 2-3 + 2-4 + 2-7 =
8 + 2 + 1 + 1/2 + 1/8 + 1/16 + 1/128 =
11,6953125
Dies nennt man eine "Festkommadarstellung", da sich das Komma immer an einer beliebigen, aber festen Stelle befindet.
Es hat sich jedoch die so genannte "Fließkommadarstellung" oder auch "Gleitkommadarstellung" durchgesetzt. Dies ist eine Darstellung von der Form:
z = m*bealso z.B.:
300 = 3*102
Dabei heißt m die "Mantisse" (dies ist in der Regel eine Festkommazahl), b ist die "Basis" und e der "Exponent". Die Basis muss dabei nicht mit der Basis der Zahlendarstellung übereinstimmen. Als Beispiel:
1228,8 = 2,4*83 b=8, e=3, m=2,4
Da man bei der Darstellung in der Fließkommadarstellung sehr viel Freiheiten hat, eine Zahl darzustellen, hat man sich auf einen Standard geeinigt. Dieser Standard ist in der Norm IEEE 754 festgeschrieben. Zum einen wird festgelegt, dass die Basis immer 2 ist, aus den gleichen Gründen, die schon bereits bei der Binärdarstellung erleutert wurden. Zum anderen wird festgelegt, wie die Bits bei einer 32bit-Darstellung (64bit-Darstellung) verteilt werden:
Im Gegensatz zur Darstellung von ganzen Zahlen, ist es bei der Darstellung von rationalen Zahlen nicht möglich, einen Zahlenbereich komplett abzubilden. Es wird immer "Lücken" geben, Zahlen können nur mit einer gewissen Genauigkeit dargestellt werden. Auch Rechenoperationen an diesen Zahlen führen zu Ungenauigkeiten.
So muss zum Beispiel für die Addition zweier Fließkommazahlen der Exponent der kleiner Zahl dem Exponenten der größeren Zahl angeglichen werden. Dies führt zu einem enormen Verlust von Genauigkeit.
Alle diese Probleme kann man nicht beheben, aber es ist sehr wichtig, sie zu kennen. So kann man seine Berechnungen so aufbauen, dass man möglichst wenig Genauigkeit verliert. Auch ist es wichtig, dass man weiß, dass bei der Darstellung als ganze Zahl diese Darstellung exakt ist, bei der Darstellung als Fließkommazahl jedoch nicht.
Welche Darstellung verwendet wird, hängt davon ab, welchen Datentyp Sie verwenden.
Vorweg ein paar Fachbegriffe: Die Umwandlung eines Datentyps in einen anderen (egal ob Zahentyp oder nicht) heißt "cast". Dabei gibt es explizite und implizite casts. Ein impliziter cast wird vom Compiler durchgeführt, ohne dass der Programmierer etwas merkt. Er funktioniert wie eine Zuweisung zwischen zwei Variablen des selben Typs, nur dass sie bei einem impliziten cast nicht den selben Typ haben. Bei einem expliziten cast muss der Programmierer explizit angeben, dass er den einen Typ in den anderen umwandeln will.
Seien Sie beim casten immer sehr vorsichtig. Nicht immer weist Sie der Compiler darauf hin, wenn durch eine Umwandlung Daten verloren gehen können. Es liegt dann in der Verantwortung des Programmierers – Ihrer Verantwortung – sich darüber Gedanken zu machen. Wenn man jedoch die nötige Vorsicht walten lässt, kann ein cast ein sehr praktisches und mächtiges Werkzeug sein.
In diesem Abschnitt sei kurz auf das casten zwischen Zahlentypen eingegangen und auch auf den Darstellungsbereich dieser Typen. Dabei unterscheiden wir strikt zwischen den Integertypen und den Floattypen. Wie bereits gesagt, bilden Integertypen einen Bereich der natürlichen Zahlen lückenlos ab.
Dabei bildet der Datentyp "Integer" je nach Compiler immer unterschiedliche Zahlenbereiche ab. Und zwar ist dieser Zahlenbereich immer dadurch definiert, dass er auf einem 32bit-System immer 32 Bit an Speicher belegt, auf einem 16bit-System 16 Bit an Speicher, usw. Natürlich nur, wenn der Compiler für das jeweilige System geschrieben wurde. Dies führt dazu, dass der Integertyp immer eine optimale Geschwindigkeit bereitstellt.
In aktuellen Compiler-Versionen von Delphi ist der Integer ein 32bit-Datentyp und identisch mit dem LongInt. Für größere Zahlen stellt Delphi auch noch einen 64bit-Integertypen, den Int64 zur Verfügung. Auch kleinere Integertypen, wie den SmallInt oder ShortInt gibt es. Am schnellsten ist jedoch immer der Integer.
Dies waren bisher alles Integertypen, die vorzeichenbehaftete Zahlen darstellen. Rechnet man immer nur mit nicht-negativen oder nicht-positiven Zahlen, so muss das Vorzeichen nicht mitgespeichert werden und statt den negativen Zahlenbereich abzubilden, kann man einen doppelt so großen positiven Zahlenbereich darstellen.
Auch hierfür bietet Delphi Datentypen und sogar einen "generischen" Datentypen analog zum Integer. Dies ist der Datentyp "Cardinal", dessen Bereich auch wieder vom Compiler abhängt. Momentan nimmt auch er 32 Bit in Anspruch und stellt damit einen Zahlenbereich von 0 bis 4294967295 dar und ist damit identisch mit dem Datentyp "Longword". Hier kann Delphi jedoch nichts Größeres anbieten, nur die kleineren Typen Word und Byte stellt es zur Verfügung.
Damit sei auch genug zur Darstellung von ganzen Zahlen gesagt. Delphi bietet logischer Weise auch Datentypen an, um reelle Zahlen darzustellen. Im Unterschied zu der Darstellung von Ganzzahlen liegt darin, dass bei der Darstellung Floats nicht nur auf den Darstellungsbereich, sondern auch auf die Genauigkeit acht gegeben werden muss.
Der Datentyp mit dem größten Darstellungsbereich ist der Extended. Er bietet außerdem eine sehr hohe Genauigkeit. Dafür genehmigt er sich aber auch satte 10 Byte Speicherplatz. Auf 32bit-Systemen am schnellsten ist der Datentyp "Single", da er 4 Byte also 32 Bit in Anspruch nimmt und somit optimal verarbeitet werden kann. Dafür ist der Darstellungsbereich wesentlich kleiner und auch die Genauigkeit ist nicht mit der des Extended zu vergleichen.
Ein guter Mittelweg, welcher auch für die meisten wissenschaftlichen Anwendungen ausreicht, ist der "Double". Er bietet eine ausreichende Genauigkeit und Größe für so ziemlich jede Anwendung. Der generische Datentyp Real ist in seiner gegenwärtigen Implementation identisch mit dem Double.
Ein Spezialfall stellt der Typ "Currency" dar. Er ist kein Fließkomma-Datentyp, also kein Float! Beim Datentyp Currency handelt es sich um einen Festkomma-Datentypen, welcher für finanz-mathematische Anwendungen entworfen wurde, da die Festkomma-Darstellung Rundungsfehler minimiert. Weitere Informationen dazu sollten in der Delphi-Hilfe unter "Reelle Typen" nachgeschlagen werden.
Nun möchte ich wie versprochen jedoch auch noch kurz auf die Umwandlung von Datentypen ineinader eingehen. Nehmen wir folgendes Beispiel:
var a : Integer; b : ShortInt; begin a := 204; b := a; ShowMessage(IntToStr(b)); end;
Hier weisen wir einem Integer zuerst den Wert 204 zu, anschließend weisen wir diesen Wert einem ShortInt zu. Die 204 sprengt jedoch den Darstellungsbereich eines ShortInts. Und was macht der Rechner: er fängt wieder von vorne an zu zählen, was in diesem Fall heißt, dass er im negativen Bereich weitermacht. Daher wird auch -52 ausgegeben und nicht 204.
Hierbei gibt Delphi keine Warnung aus! Solche Aktionen liegen in der Verantwortung des Programmierers!
Delphi Language war früher "Object Pascal". Dieser Name impliziert eine Funktionalität, welche in der Welt der Programmierung nicht mehr wegzudenken ist: die objektorientierte Programmierung, kurz OOP. Ich kann diese Art der Programmierung hier nicht in der Ausführlichkeit besprechen, wie sie es verdient hätte, man kann ganze Bücher über OOP schreiben.
Jedoch wäre dies kein Crashkurs über Delphi, wenn die OOP keinen Platz darin hätte. Und so werde ich im Folgenden eine kurze Einfühung zur OOP im Allgemeinen geben und dann aufzeigen, wie sie in Delphi umgesetzt wurde und verwendet werden kann. Der Anfang mag etwas theoretisch sein, jedoch bietet die OOP dem Programmierer enorme Möglichkeiten, sein Programm übersichtlicher und auch zeitsparender zu schreiben.
Nehmen wir als Objekt ein Rechteck her. Dieses Rechteck hat verschiedene Eigenschaften, wie z.B. Höhe und Breite oder auch seine Position im Raum. Auch kann man mit einem Rechteck bestimmt Aktionen verbinden: Man kann es verschieben oder auch seinen Flächeninhalt berrechnen.
Diese Darstellung von Objekten wurde auf die Informatik übertragen. Man ordnet einem Objekt in der Informatik Methoden (das sind an eine Klasse gebundene Prozeduren oder Funktionen) und Eigenschaften (auch "Felder" genannt) zu (in Delphi gibt es noch "Properties", das ist aber etwas anderes, daher lasse ich das im Englischen). Dadurch wird ein erster Vorteil der OOP deutlich: sie schafft Ordnung, weil sofort klar wird, welche Methode und welche Information wohin gehören.
Objekte gleicher Art ("Rechtecke") fasst man als "Klasse" zusammen. Eine Klasse beschreibt also, welche Methoden und Eigenschaften ein solches Objekt habe muss. Ein "wirkliches", verwendbares Objekt nennt man auch eine "Instanz" einer Klasse. Man kann beliebig viele Instanzen einer Klasse anlegen. Logisch: Es gibt ja auch beliebig viele Rechtecke. ;-)
Elementarer Bestandteil der OOP ist die Vererbung. Um dies deutlich zu machen, ziehen wir ein weiteres Beispiel heran. Man kann sich eine Klasse "geometrische Form" vorstellen. Diese geometrische Form wird eine Position im Raum besitzen und eine Fläche (welche natürlich auch Null sein kann) und man kann sie auch verschieben. Dabei können wir über die Funktion der Flächenberechnung nur sagen, dass es sie geben wird, aber sie wird für die Klasse der geometrischen Formen noch keine Bedeutung haben. Man bezeichnet sie als "abstrakt".
Nun kann man von einer Klasse (wie z.B. der geometrischen Formen) weitere Klassen "ableiten". Das heißt, man bildet eine Klasse als Spezialfall einer anderen Klasse. So ist ein Rechteck ein Spezialfall einer geometrischen Form. Dabei "erbt" ein Rechteck die Eigenschaft "Position" und die Methode zur Verschiebung. Es besitzt die neuen Eigenschaften "Höhe" und "Breite". Außerdem füllt es die Funktion zur Flächenberechnung mit Leben.
Wir werden später sehen, dass die Vererbung sehr praktisch sein kann. So muss man z.B. die Methode zur Verschiebung einmal schreiben und kann sie dann für alle geometrischen Formen (Rechteck, Kreis, Dreieck, ...) verwenden, ohne sie nochmals neu schreiben zu müssen. Auch die Position muss man nicht neu implementieren.
Ein weiterer wichtiger Bestandteil der OOP ist die "Sichtbarkeit". So werden oft Informationen in Objekten "gekapselt", das heißt, sie sind nur innerhalb des Objektes sichtbar und können von außen nur über einen festen Satz von Methoden manipuliert werden. Dieser Satz von Methoden stellt dann eine Schnittstelle zwischen der Außenwelt und den Informationen dar.
Dabei gibt es in jeder Programmiersprache verschiedene Stufen der Sichtbarkeit (nicht alle werden in Delphi verwendet). Es gibt Methoden und Eigenschaften, welche nur in der betreffenden Klasse sichtbar sind. Dann gibt es Methoden und Eigenschaften, welche nur in der betreffenden Klasse und in allen abgeleiteten Klassen sichtbar sind. Und es gibt Methoden und Eigenschaften, welche öffentlich sichtbar sind.
Verschiedene Programmiersprachen bieten ja nach ihren Eigenarten noch weitere Arten der Sichtbarkeit und manche Programmiersprachen bieten im Gegenzug auch manche der oben genannten Sichtbarkeiten nicht oder nur in angewandelter Form.
Dies war wirklich nur ein winziges bisschen Theorie, eigentlich nur eine Einleitung, damit die Praxis etwas besser zu verdauen ist. Und mit der möchte ich nun weiter machen, weil dann vieles von dem, was ich oben beschrieben habe, klarer werden wird.
Hier gibt es wieder etwas für Sie zu tun, sie können folgende Quelltexte in Ihrem Delphi mitschreiben. Legen Sie dazu erst einmal eine neues Projekt an und speichern Sie es unter einem sinnvollen Namen (also nicht gerade "Project1" ;-)). Wählen Sie dann im Menü "Datei"->"Neu"->"Unit". Das Gerüst einer leeren Unit sollte erscheinen, wahrscheinlich mit Namen "Unit2". Speichern Sie auch diese Datei und zwar unter dem Namen "geomForm.pas", denn genau das wird diese Datei enthalten: die Klasse für geometrische Objekte. Der neue Name sollte nun auch automatisch im Quelltext verewigt sein.
Zuerst einmal sei hier die Definiton einer Klasse in Delphi gezeigt. Diese Deklaration erfolgt – wie jede andere auch – im interface-Teil des Programmes:
type TgeomForm = class end;
Dies ist das mindeste, was man für die Definition einer Klasse in Delphi braucht. Damit kann man natürlich noch nicht viel anfangen, denn außer des Namens wurde noch nichts festgelegt. Es sollen nun im folgenden die verschiedenen Eigenschaften und Methoden für eine geometrische Form hinzugefügt werden.
Dabei hat Delphi (bis zu Version 7) die Eigenart, dass die geringste Sichtbarkeit nicht die ist, in der der Elemente nur innerhalb einer Klasse sichtbar sind, sondern die geringste Sichtbarkeit ist die, in der Elemente nur in der Klasse und in anderen Klassen der gleichen Unit sichtbar sind. Diese Sichtbarkeit nennt sich "private".
Entsprechend gibt es auch die Sichtbarkeit für die Klasse selbst und abgeleitete Klassen, sondern diese Elemente sind auch für alle anderen Klassen in der selben Unit sichtbar! Diese Sichtbarkeit nennt sich "protected". Dies ist ein deutlicher Unterschied zu anderen Programmiersprachen, wie C++ oder Java, wo die Sichtbarkeiten denselben Namen haben, die Erweiterung der Sichtbarkeit auf die gleiche Unit jedoch nicht vorhanden ist!
Um dieses Problem zu umgehen, kann man einfach für jede Klasse eine Unit reservieren. Dies ist auf Grund der übersichtlichkeit sowieso sehr nützlich und man sollte es sich schon sehr gut überlegt haben, bevor man zwei Klassen in einer Unit anlegt.
Nun zurück zum Beispiel einer geometrischen Form: Die Position soll als private deklariert werden und aus einer x- und einer y-Koordinate bestehen. Diese Koordinaten sollen als Integer deklariert werden und die Pixel auf der Zeichenfläche des Bildschirms darstellen.
Die Definition der Klasse sieht nun so aus:
type TgeomForm = class private Fx : Integer; Fy : Integer; end;
Man sieht, dass für "Fy" nicht erneut der Bezeichner "private" voran gestellt werden musste. Dies liegt daran, dass Delphi immer die Sichtbarkeit des vorangehenden Elementes verwendet, wenn vom Programmierer nichts anderes festgelegt wird. Wird für das erste Element keine Sichtbarkeit angegeben, so wird Standardmäßig "public" verwendet, das heißt, das Element ist öffentlich sichtbar.
Es ist übrigens kein Schreibfehler, dass den Koordinaten ein "F" voran gestellt wurde: es ist üblich, als "private" deklarierte Eigenschaften (nicht die Methoden) mit einem vorangestellten "F" (für "Feld" bzw. "field") zu kennzeichnen. Wozu dies gut ist, wird später noch deutlich werden, wenn die Properties beschrieben werden.
Als nächstes soll die Methode zur Verschiebung einer geometrischen Form eingebaut werden. Dieses Beispiel zeigt auch, wie man die Methoden eines Objektes konkret implementiert. Dazu muss man sie zuerst deklarieren:
type TgeomForm = class private Fx : Integer; Fy : Integer; public procedure verschieben(dx, dy : Integer); end;
Achten Sie bitte darauf, dass die Prozedur zum Verschieben öffentlich verwendbar sein soll und daher mit einem vorangestellten "public" ausgestattet wurde. Ansonsten wird sie wie eine ganz normale Prozedur deklariert.
Nun muss diese Prozedur noch mit Leben gefüllt werden. Dies tut man natürlich im implementation-Teil des Programmes.
procedure TgeomForm.verschieben(dx, dy: Integer); begin self.Fx := self.Fx + dx; self.Fy := self.Fy + dy; end;
Dieser Codeabschnitt wird nun etwas genauer betrachtet. Die erste Zeile gibt an, welche Methode hier implementiert werden soll. Dabei wird die volle Deklaration der Methode (inkl. der Angabe, ob es sich um eine Prozedur oder Funktion handelt) um die Angabe erweitert, zu welcher Klasse die Methode gehört, in diesem Fall "TgeomForm".
Die Implementation einer Methode folgt ansonsten den gleichen Regeln wie eine normale Prozedur oder Funktion. Jedoch wird oben schon deutlich, dass für die Verwendung innerhalb von Klassen noch ein paar Bezeichner hinzugefügt wurden, so z.B das Wort "self". Dieses Wort bezeichnet die Instanz, zu der die Methode gehört. Beachten Sie: es bezeichnet wirklich das konkrete Objekt (die Instanz) und nicht nur die Klasse!
Somit wird auch deutlich, wie man auf die Eigenschaften eines Objektes zugreift, sofern sie sichtbar sind: der Name des Objektes und dann – durch einen Punkt getrennt – der Name der Eigenschaft. Entsprechend ruft man übrigens auch die entsprechenden Methoden auf.
Bevor nun die Methode zur Flächenberechnung implementiert will, soll erst einmal die Verwendung einer solchen Klasse demonstriert werden und dann auch noch die Erstellung einer abgeleiteten Klasse vorgestellt werden. Denn das ist die Voraussetzung, um die abstrakte Methode zur Flächenberechnung korrekt einzuführen.
Um eine Klasse zu verwenden, müssen Sie dem Compiler sagen, wo er diese Klasse findet, also in welcher Unit sie deklariert und implementiert wurde. Solche Angaben macht man im "uses"-Abschnitt einer Unit. Wählen Sie die Unit, in welcher sich Ihre Form befindet (wahrscheinlich "Unit1") und suchen Sie dort den uses-Abschnitt. Erweitern Sie ihn so, dass er wie folgt aussieht:
uses
Windows, Messages, SysUtils, Variants, Classes, Graphics, Controls, Forms, Dialogs, geomForm;
Nachdem der Compiler nun weiß, wo er zu suchen hat, kann man die Klasse verwenden. Es ist egal, wo Sie das tun, man kann es auch direkt bei Erstellung der Form machen. Klicken Sie also doppelt auf "Form1", um die Methode für das entsprechende "OnCreate"-Ereignis anzulegen. Bauen Sie dann folgenden Quelltext ein, er wird nur ein wenig weiter unten erklärt.
(Folgender Quelltext ist noch nicht ganz korrekt, es fehlt etwas, das sich "Speicherschutzblock" nennt, darauf werde ich im Kapitel über Exceptions noch eingehen. Es funktioniert auch ohne und für unsere Zwecke reicht das erst einmal.)
procedure TForm1.FormCreate(Sender: TObject); var geomForm : TgeomForm; begin geomForm := TgeomForm.Create; geomForm.verschieben(10,10); geomForm.Free; end;
Was passiert hier? Zuerst einmal wird eine Variable "geomForm" vom Typ "TgeomForm" wie jede andere Variable auch deklariert. Doch dies reicht bei Objekten jedoch nicht. Um ein Objekt zu verwenden, muss man es erst noch erstellen. Bei diesem Vorgang erst wird für das Objekt Speicher reserviert. Dies ist übrigens auch der Vorgang, den man als "Instanz erstellen" bezeichnet.
Das Erstellen eines Objektes funktioniert über einen Konstruktor, was auch nur eine besondere Methode ist und daher genauso verwendet wird. Diese Methode ist in diesem Fall "Create". Nun stellt sich die Frage, woher diese Methode kommt, denn sie wurde in TgeomForm weder implementiert noch deklariert.
Sie kommt aus der Klasse "TObject". Denn alle Klassen, bei denen nicht explizit angegeben wird, von welcher sie abgeleitet werden sollen, werden implizit von TObject abgeleitet und erben somit auch alle Methoden und Eigenschaften von TObject. Um hier mal die Delphi-Hilfe zu zitieren: "TObject ist der Ausgangspunkt der Klassenhierarchie, sozusagen der Urahn aller Objekte und Komponenten."
Nachdem das Objekt erstellt wurde, wird als Beispiel die Methode zum Verschieben aufgerufen. Hier sollten keine weiteren Überraschungen zu sehen sein, der Aufruf ist ansich wie der jeder anderen Methode, nur das man noch das Objekt (nicht die Klasse) angeben muss, zu dem die Methode gehört.
In der nächsten Zeile wird das Objekt "freigegeben". Das führt dazu, dass das Objekt wieder aus dem Speicher entfernt und und der entsprechende Speicherbereich wieder freigegeben wird. Auch diese Methode stammt von "TObject" und wird von dort übernommen. Es gibt auch noch die Methode "Destroy". Diese tut im Prinzip dasselbe, jedoch prüft "Free" noch, ob das Objekt überhaupt existiert, bevor "Destroy" aufgerufen wird. Dadurch werden Fehler vermieden. Rufen Sie also immer "Free" auf.
Nun ist klar, wie man eine Klasse und die daraus instanzierten Objekte verwendet. Nun soll gezeigt werden, wie man von einer Klasse eine andere ableitet. Im folgenden wird dies am Beispiel einer Klasse für Rechtecke demonstriert.
Das Ableiten einer Klasse von einer anderen ist nicht sehr schwer. Die Deklaration erfolgt fast genauso wie bei einer "normalen" Deklaration, mit der Ausnahme, dass man noch angibt, von welcher Klasse die deklarierte Klasse abgeleitet wird. Erstellen Sie eine weitere Unit und speichern Sie als "rechteck.pas" ab. Erstellen Sie einen uses-Abschnitt, der ausschließlich den Eintrag "geomForm" enthält. Schreiben Sie außerdem folgendes in den interface-Teil:
type TRechteck = class(TgeomForm) end;
Damit ist das Ableiten einer Klasse von einer anderen eigentlich schon fertig. "TRechteck" ist nun ein Nachfahre von "TgeomForm" und besitzt somit auch die Methode "verschieben". Nun kann man aber über ein Rechteck ein bisschen mehr aussagen, als man über eine allgemeine, geometrische Form sagen kann. So hat ein Rechteck bespielsweise Höhe und Breite! Und diese beiden Werte sollen in der Klasse "TRechteck" gespeichert werden.
type TRechteck = class(TgeomForm) private Fhoehe : Integer; Fbreite : Integer; end;
Diese Eigenschaften (die wiederrum nur in "TRechteck" und Klassen in der gleichen Unit sichtbar sind) kommen zu den Eigenschaften hinzu, welche schon von "TgeomForm" geerbt wurden. Nur gewinnen wir damit nichts, weil wir mit "TRecheck" noch nicht mehr anfangen können als mit "TgeomForm".
Um einen Gewinn zu erreichen, erweitern wir nun "TgeomForm" erst einmal um eine abstrakte Methode, also eine Methode, welche in "TgeomForm" zwar deklariert aber noch nicht implementiert wird. Sie ahnen es sicherlich schon, es geht um die Flächenberechnung für ein geometrisches Objekt. Erweitern Sie die Klasse "TgeomForm" so, dass sie wie folgt aussieht:
type TgeomForm = class private Fx : Integer; Fy : Integer; public procedure verschieben(dx, dy : Integer); function flaeche : Integer; virtual; abstract; end;
Das Bedarf nun doch einiger Erklärung. Der erste Teil sollte klar sein: Die Klasse wird um eine Funktion mit Namen "flaeche" erweitert, welche einen Integer zurückliefert - eben die Fläche. Aber was bedeuten die beiden Schlüsselworte dahinter?
Zuerst einmal zum Wort "virtual". Dies bedeutet, dass diese Methode in von "TgeomForm" abgeleiteten Klassen überschrieben (also mit einer neuen Bedeutung versehen) werden darf. Die Methode aus der Mutterklasse ist in der abgeleiteten Klasse dann nicht mehr zu sehen, nur die "neue" Methode gleichen Namens. Mehr dazu gibt es noch im nächsten Abschnitt.
Das Wort "abstract" sollte nach dem Theorie-Teil schon fast selbst erklärend sein. Es signalisiert dem Compiler, dass es sich bei der Methode "flaeche" um eine abstrakte Methode handelt, sie also in "TgeomForm" nur deklariert, aber nicht implementiert (mit Leben gefüllt) wird. Das wird dann in einer der abgeleiteten Klassen gemacht, was ja auch der Plan war, als wir anfingen, die Klasse "TgeomForm" zu erweitern. ;-)
Und diesen Plan werden wir nun vervollständigen, indem wir schlussendlich die Methode zur Flächenberechnung in der Klasse "TRechteck" deklarieren und implementieren. Die Deklaration sieht so aus:
type TRechteck = class(TgeomForm) private Fhoehe : Integer; Fbreite : Integer; public function flaeche : Integer; override; end;
Eine Mehtode, welche in der Mutterklasse als "abstract" deklariert wurde, muss also in der abgeleiteten Klasse, sofern sie dort implementiert werden soll, nochmals deklariert werden. Jedoch reicht eine einfache Deklaration nicht aus, sondern es muss auch noch das Schlüsselwort "override" hinzugefügt werden. Das signalisiert dem Compiler, dass die Methode der Mutterklasse überschrieben werden soll.
Nun muss diese Methode noch implementiert werden, natürlich im implemenation-Teil der Unit:
function TRechteck.flaeche: Integer; begin result := Fhoehe*Fbreite; end;
Diese Funktion würde nun also die Fläche des Rechtecks zurück geben. Wenn nur irgendwo jemals definiert worden wäre, welche Höhe und Breite das Rechteck hat. Denn so, wie die Klasse momentan aussieht, kann man das gar nicht bestimmen, Höhe und Breite sind immer Null! Darum müssen Sie sich also noch kümmern. Fürs Erste wird es ausreichen, wenn man beim Erstellen (Sie erinnern sich: "Create") angeben kann, wie groß das Rechteck sein muss. Doch bevor wir uns darum kümmern, noch ein kleiner Exkurs zum Überschreiben von Methoden.
Im vorigen Abschnitt wurde gezeigt, wie man eine abstrakte Methode überschreiben kann. Dies geht jedoch auch mit nicht-abstrakten Methoden, also mit Methoden, die in der Mutterklasse implementiert wurden. Das macht die ganze Sache etwas kompliziert.
Sehen wir uns die folgende Verwendung an, dieses Mal mit einem Beispiel, welches nicht in den Rest passt:
type TAuto = class(TObject) private public function drive : String; end; {...} function TAuto.drive : String; begin result := 'TAuto.drive'; end;
type TOpel = class(TAuto) private public function drive : String; end; {...} function TOpel.drive: String; begin result := 'TOpel.drive'; end;
Und dazu folgende Verwendung der beiden Klassen:
var auto : TAuto; begin auto := TOpel.Create; ShowMessage(auto.drive()); end;
Beachten Sie dabei, dass "auto" zwar als "TAuto" deklariert wurde, aber der Konstruktor von "TOpel" aufgerufen wird, außerdem sollten Sie beachten, dass die Methode in "drive" in der Klasse "TAuto" nicht als "virtual" deklariert wurde.
Führt man diesen Code nun aus, sieht man, dass die Methode "drive" aus der Klasse "TAuto" aufgerufen wird, obwohl wir eine Instanz der Klasse "TOpel" erzeugt haben. Methoden mit diesem Verhalten nennt man "statisch", es ist die Standardeinstellung für Methoden. Bei statischen Methoden wird also immer die Methode der Klasse aufgerufen, die deklariert ("auto : TAuto") wurde und nicht die Methode der Klasse, die instanziert wurde.
Deklariert man die Methode "drive" in der Klasse "TAuto" nun als "virtual" und ergänzt man die Methode "drive" in der Klasse "TOpel" um ein "override", so ergibt obiger Quelltext ein anderes Ergebnis: Dann wird nämlich die Methode aus der Klasse "TOpel" ausgeführt, also der Klasse, die wir instanziert haben! Die "virtuelle" Methode aus der Klasse "TAuto" wurde also "überschrieben" (override).
Es gibt übrigens außer virtuellen Methoden auch noch "dynamische" Methoden, welche mittels des Schlüsselwortes "dynamic" an der Stelle von "virtual" deklariert werden. Dynamische Methoden unterscheiden sich in der Verwendung nicht von virtuellen, der Unterschied liegt lediglich in der internen Umsetzung: Virtuelle Methoden sind auf eine hohe Geschwindigkeit optimiert, dynamsiche Methoden auf einen geringen Speicherverbrauch.
Nun sollte der Quelltext aus dem vorigen Abschnitt klarer werden: Die Methode "flaeche" in TgeomForm ist virtuell, weil sie von den abgeleiteten Klassen überschrieben werden muss. Dies macht Sinn, denn sie ist auch abstrakt (also nicht implementiert) ein Aufruf dieser Methode würde daher nicht nur keinen Sinn machen, sondern einen Fehler produzieren. Was nicht da ist, kann man nicht aufrufen. Daher müssen abstrakte Methoden auch immer als virtuell oder dynamisch deklariert werden.
Und nun weiter mit unserem bisherigen Beispiel!
Wie bereits gesagt, ist der Konstruktor der Teil einer Klasse, welcher neue Instanzen eben dieser Klasse erzeugt. Er ist also nicht an ein Objekt, sondern an die entsprechende Klasse gebunden. Der "Ur"-Konstruktor ist in der Urklasse "TObject" deklariert, aber er kann in jeder Klasse neu deklariert und implementiert werden, solange man daran denkt, jeweils den Konstruktor der Vorfahrklasse auch noch auszurufen. Dies muss man tun, damitr auch das, was in den Muttterklassen im Konstruktor gemacht wird, erledigt wird.
In unserem Fall möchten wir, dass der Konstruktor auch noch das Setzen von Höhe und Breite mit erledigen soll. Dazu soll der Konstruktor nicht "normal" aufgerufen werden, sondern direkt noch die beiden Maße als Parameter mitgegeben bekommen. Dazu muss man den Konstruktor erst einmal wieder deklarieren. Dabei wird ein Konstruktor weder als Funktion noch als Prozedur deklariert, sondern als ... Konstruktor. ;-)
type TRechteck = class(TgeomForm) private Fhoehe : Integer; Fbreite : Integer; public constructor create(hoehe, breite : Integer); function flaeche : Integer; override; end;
Bis auf das Schlüsselwort "constructor" sieht der Konstruktor in der der Deklaration also aus, als wäre er eine ganz normale Methode. Was er nicht ist, denn, wie bereits erwähnt, er ist nicht an eine Instanz, sondern an die Klasse gebunden. Nun zur Implementation, die eigentlich auch keine Überraschungen bereit hält:
constructor TRechteck.create(hoehe, breite: Integer); begin inherited create; FHoehe := hoehe; FBreite := breite; end;
Das einzig wirklich neue an diesem Quelltext ist die Zeile, welche mit den Schlüsselwort "inherited" beginnt. Leitet man den Aufruf einer Methode (in diesem Fall "create") mit dem Schlüsselwort "inherited" ein, so signalisiert man dem Compiler damit, dass in diese Fall die entsprechende Methode der Mutterklasse aufgerufen werden soll und nicht die Methode der aktuellen Klasse. Hier heißt das also: es wird der Konstruktor von "TgeomForm" aufgerufen.
Der Rest des Konstruktors ist einfach, es werden die per Parameter übergebenen Maße in den entsprechenden Eigenschaften gespeichert, damit sie später zur Verfügung stehen. Ich habe an dieser Stelle aus Absicht darauf verzichtet, über "self.FHoehe" bzw. "self.Fbreite" auf die Eigenschaften zuzugreifen, um Ihnen zu zeigen, dass es bei Eindeutigkeit der Bezeichner auch anders geht.
An dieser Stelle möchte ich noch auf einen Fehler hinweisen, der sehr gerne begangen wird, nämlich dann, wenn es um die Zuweisung von Objekten geht. Nehmen wir nur für das nachfolgende Beispiel an, die Höhe und Breite eines Rechtecks könnten von außen (über "hoehe" und "breite") manipuliert werden. Nehmen wir weiterhin an, es wurden zwei Rechtecke deklariert, eines wurde erzeugt:
var r1, r2 : TRechteck; begin r1 := TRechteck.Create(50, 10); r2 := r1; r2.hoehe := 10; r2.breite := 10; ShowMessage(IntToStr(r1.flaeche)); end;
Die Meldung zeigt in diesem Fall nicht "500", wie man zuerst denken würde, da "r1" ja mit den Maßen 50 und 10 erzeugt wurde, sondern die Meldung zeigt "100", was der Fläche von "r2" entspricht. Der Grund dafür ist, dass Objekte "Referenzdatentypen" sind und sich bei Zuweisungen so verhalten, wie ich es auch schon bei Arrays beschrieben habe. Die Zuweisung "r2 := r1" erzeugt kein neues Objekt, sondern "r2" verweist auf dasselbe Objekt wie "r1", ist sozusagen nur ein anderer Name für dasselbe Objekt, weshalb die Fläche hinteher auch 100 und nicht 500 ist.
Der Konstuktor ist nun beschrieben, jetzt werfen wir nochmals einen Blick auf die Verwendung der neu erstellten Objekte. Allerdings nicht bevor wir uns nicht das Gegenteil des Konstruktors angesehen haben. ;-)
Obwohl in diesem Beispiel nicht benötigt, sei hier noch kurz auf das Gegenstück zum Konstruktor, den "Destruktor" eingegangen. Er ist dafür zuständig, dass das Objekt, welches zuvor durch den Konstruktor erzeugt wurde, nach Verwendung auch wieder aus dem Speicher entfernt wird. Dabei wird der Destruktor als Methode der Instanz aufgerufen, welche "vernichtet" werden soll.
Der Destruktor wird fast wie der Konstruktor deklariert, mit den Ausnahmen, dass anstatt des Schlüsselwortes "constructor" das Schlüsselwort "destructor" verwendet wird und er den Destruktor der Mutterklasse überschreibt, also mit einem "override" deklariert wird. Dies ist nur beim Destruktor nötig, da der Konstruktor ja über die Klasse und nicht über eine Instanz aufgerufen wird und somit eindeutig ist, welcher Konstruktor aufgerufen wird. Der Name des Destruktors ist immer "destroy".
destructor destroy; override;
Wichtig ist, dass im Destruktor ebenfalls der Destruktor der Vorwahrklasse aufgerufen wird, jedoch am Ende des eigenen Destruktors:
destructor TmyClass.destroy; begin {...} inherited destroy; end;
In "Ihrem" Destruktor sollten Sie vorm Aufruf des Destruktors der Mutterklasse allen Speicher freigeben, den Sie innerhalb der Instanz, welche freigegeben werden soll, belegt haben. Meist wird es sich dabei um weitere Objekte handeln, welche Sie in Ihrer Klasse instanzieren.
Überschreiben und implementieren Sie immer den Destruktor "destroy", aber niemals die Methode "free ". Diese wird zwar immer aufgerufen, wenn man ein Objekt freigeben möchte, diese ruft aber wiederrum "destroy" auf. Die Methode "free" enthält lediglich noch eine Überprüfung, ob das Objekt, welches freigegeben werden soll, überhaupt noch existiert und vermeidet somit Fehler. Also: Finger davon, die eigentliche Arbeit wird in "destroy" erledigt.
Da wir in diesem Beispiel keinerlei Objekte innerhalb unserer Klassen instanzieren, sondern lediglich primitive Datentypen verwenden, brauchen wir in diesen Klassen auch keine Destruktoren.
Bitte beachten Sie zum Freigeben von Objekten auch den Teil dieses Crashkurses über Exceptions!
Die Verwendung soll noch einmal die "Verwandschaft" von Klassen verdeutlichen. Eine kleine Vorbereitung müssen Sie jedoch noch vornehmen, platzieren Sie bitte eine Label, zwei Editfelder und einen Button auf der Form. Ändern Sie den Namen der Editfelder über den Objektinspektor auf "ed_hoehe" und "ed_breite" (die entsprechende Eigenschaft heißt "name") und sorgen Sie dafür, dass beide Editfelder beim Programmstart leer sind, indem Sie die Eigenschaft "text" entsprechend ändern. Geben Sie dem Label den Namen "la_flaeche", es soll anfangs keinen Text anzeigen (Eigenschaft "Caption" ändern). Den Button nennen Sie "bt_flaeche", seinen Titel ändern Sie auf "Fläche berechnen".
Klicken Sie nun doppelt auf den Button, um die OnClick-Methode aufzurufen. Deklarieren Sie dort die Variablen "hoehe", "breite" und "fleche" als Integer. Lesen Sie mittels "StrToInt" die Höhe und die Breite aus den entsprechenden Editfeldern ein! Deklarieren Sie außerdem noch eine Variable "rechteck" vom Typ "TRechteck". Bei einem Objekt wie "rechteck" reicht es, wie inzwischen bekannt sein sollte, jedoch nicht aus, dieses nur deklariere, Sie müssen es auch noch erzeugen. Somit sieht die OnClick-Methode bisher so aus:
procedure TForm1.bt_flaecheClick(Sender: TObject); var hoehe, breite, flaeche : Integer; rechteck : TRechteck; begin hoehe := StrToInt(ed_hoehe.Text); breite := StrToInt(ed_breite.text); rechteck := TRechteck.create(hoehe, breite);
Wie man an die Fläche herankommt, sollte klar sein:
flaeche := rechteck.flaeche;
Schließlich noch das Objekt freigeben und das Ergebnis ausgeben:
rechteck.free;
la_flaeche.Caption := IntToStr(flaeche);
end;
Hier wird jedoch noch nicht so ganz deutlich, welchen Vorteil der Vererbung liefert. Das wird erst deutlich, wenn wir noch eine weitere Klasse einführen, nämlich die Klasse "TKreis". Wie das geht, sollte klar sein. Ein Kreis hat einen Radius anstatt Höhe und Breite, entsprechend müssen Eigenschaften, Konstruktor und die Methode zur Berechnung der Fläche angepasst werden.
Ist das geschehen, kann man sich folgende Situation vorstellen: Man schreibt ein Grafikprogramm und möchte geometrische Formen verwalten, wobei es egal sein soll, ob es sich dabei um Rechtecke, Kreise oder noch andere Formen handelt. Eine Anwendung, welche das Grafikprogramm bieten soll, ist, die Gesamtfläche aller Formen zu errechnen. Mit OOP und Vererbung kein Problem!
interface type TgeomFormArray = Array of TgeomForm; implementation function gesamtflaeche (formen : TgeomFormArray) : Integer; var i : Integer; begin result := 0; for i:=0 to High(formen) do result := result + formen[i].flaeche; end;
Ich habe hier nur einen Codeschnipsel aufgeschrieben, dessen Hauptaussage aber klar sein sollte. Zuerst wird ein neuer Typ definiert, ein Array aus geometrischen Formen. Dies ist nötig, damit man hinterher eine Variable diesen Typs an eine Funktion übergeben kann, definiert man dafür keinen neuen Typ, macht Delphi Probleme. Eine Variable diesen Typs wird dann der Funktion "gesamtflaeche" übergeben, diese Variable soll alle Formen enthalten, die im Programm verwendet werden (also z.B. fünf Rechtecke und drei Kreise).
Sie bemerken: das Array ist ein Array von "TgeomForm", enthält aber Daten der Typen "TRechteck" und "TKreis"! Dies wird nochmals in der Schleife deutlich, welche alle Elemente des Arrays durchläuft: Durchlaufen wird ein Array von geometrischen Formen, für jede dieser Formen wird die Funktion "flaeche" aufgerufen. Dies geht, weil die Funktion "flaeche" abstrakt in "TgeomForm" deklariert wurde und somit bekannt ist, dass jedes dieser Elemente sie besitzt. Der Code, welcher beim Aufruf ausgeführt wird, ist jedoch jener der Datentypen "TRechteck" bzw. "TKreis", je nachdem, das die aktuelle geometrische Form ist!
Nun sollte klar sein, welcher Vorteil die Vererbung bietet: Eine abgeleitete Klasse kann die Methoden der Mutterklasse überschreiben und ihnen somit eine völlig neue Bedeutung geben. Dies nennt man übrigens auch "Polymorphie". Bei einer abstrakten Methode, wie in diesem Fall, wird durch der Methode das Überschreiben überhaupt erst eine Implementation gegeben, man könnte aber auch eine bereits implementierte Methode überschreiben, sofern auch sie mit dem Schlüsselwort "virtual" deklariert wurde.
Bisher wurde nur gezeigt, wie man von außen Methoden verwendet, jedoch nicht, wie man von außen die Eigenschaften von Objekten manipuliert. Es hat sich durchgesetzt, dass man auch die Eigenschaften, welche eigentlich von außen manipuliert werden dürfen (also nicht "private" oder "protected" wären), nicht einfach in den public-Teil zu schreiben, sondern sie der Außenwelt durch so genannte "properties" zur Verfügung zu stellen. Damit behält der Programmierer der entsprechenden Klasse die Kontrolle darüber, was mit den Eigenschaften geschieht.
Im Folgenden soll erst einmal die Deklaration einer property gezeigt werden, wieder anhand der Klasse "TgeomForm".
type TgeomForm = class private Fx : Integer; Fy : Integer; public procedure verschieben(dx, dy : Integer); function flaeche : Integer; virtual; abstract; property x : Integer read Fx write Fx; property y : Integer read Fy write Fy; end;
Die Deklaration ist recht einfach zu verstehen: Das Schlüsselwort "property" signalisiert dem Compiler, was nun auf ihn zukommt, dann folgen Name und Typ der property. Anstatt hier jedoch Schluss zu machen, benötigt der Compiler nun die Information, wohin er die Aufrufe der property "umleiten" soll, denn eine property ansich enthält keinen Wert, sie holt ihn nur woanders her bzw. setzt ihn woanders.
Woher eine property ihren Wert holen oder wo sie einen neuen Wert setzen soll, das wird über die Schlüsselwörter "read" und "write" festgelegt. In diesem Fall wird der Wert für die property "x" aus der privaten Eigenschaft "Fx" geholt und wenn "x" ein Wert zugewiesen wird, wird diese Zuweisung auch dorthin "weitergeleitet". Hier wird übrigens auch klar, weshalb man bei privaten Eigenschaften noch ein "F" vor den Namen schreibt: damit man hinterher eine property mit dem richtigen Namen einführen kann. Verwendet wird eine solche property übrigens wie folgt:
var myGeomForm : TgeomForm; {...} myGeomForm.x := 5;
Also nichts anderes als bei den privaten Eigenschaften auch. Jetzt stellen Sie sich wahrscheinlich die Frage, wo denn nun der Vorteil von properties liegt. Das wird deutlich, wenn man die Deklaration mal ändert:
type TgeomForm = class private Fx : Integer; Fy : Integer; procedure setX(const value : Integer); function getX : Integer; public procedure verschieben(dx, dy : Integer); function flaeche : Integer; virtual; abstract; property x : Integer read getX write setX; property y : Integer read Fy write Fy; end;
Hier wurde nur die Deklaration für die property "x" verändert: Es wird von "x" aus nun nicht mehr auf die private Eigenschaften "Fx" zugegriffen, sondern die Aufrufe werden an die Funktion "getX" und die Prozedur "setX" weitergeleitet. Wird also "x" wieder (wie oben bereits gezeigt) der Wert 5 zugewiesen, wird nun die Prozedur "setX" aufgerufen und als Parameter "value" die 5 übergeben. Wird "x" abgefragt, so wird die Funktion "getX" aufgerufen und das Ergebnis als "x" zurückgegeben.
Der Vorteil dieser Technik zeigt sich in der Implementation der Methode "setX":
procedure TgeomForm.setX(const value: Integer); begin if value >= 0 then Fx := value; end;
In dieser Prozedur wird also zuerst geprüft, ob "x" auf einen plausiblen Wert gesetzt werden soll (in diesem Fall sollen alle Werte größer oder gleich Null sein), und nur wenn dies der Fall ist, wird der Wert im privaten "Fx" auch wirklich gesetzt, der Wert also letzten Endes geändert.
Das Verwenden von get- und set-Methoden gibt dem Programmierer einer Klasse also Möglichkeiten der Kontrolle, zusätzlich zu der Möglichkeit, den Hinterbau einer Eigenschaft (z.B. "x") komplett zu verändern (in diesem Fall wurde der Hinterbau auf die Methoden "getX" und "setX" umgestellt), ohne dass derjenige, der die Klasse nur verwendet, etwas bemerkt.
Eine Erweiterung der normalen Properties stellen die Array-Properties dar. Mit ihnen hat man die Möglichkeit, beim Zugriff auch noch einen oder mehrere Indizies anzugeben, also auf die Property zuzugreifen wie auf ein Array. Folgendes Beispiel soll den Zugriff auf x- und y-Position einer geometrischen Form mittels Indizes aufzeigen, dabei soll man die x-Position mit dem Index "0" erreichen und die y-Koordinate mittels "1":
type TgeomForm = class private Fx : Integer; Fy : Integer; procedure setPos(index : Integer; const value : Integer); function getPos(index : Integer) : Integer; public {...} property position[index : Integer] : Integer read getPos write setPos; end;
Die get- und set-Methoden erhalten also einen zusätzlichen Parameter, der den übergebenen Index angibt. Eine Implementation sähe dann (am Beispiel der set-Methode) so aus:
procedure TgeomForm.setPos(index : Integer; const value : Integer); begin case index of 0: Fx := value; 1: Fy := value; end; end;
Ein Zugriff auf diese Property könnte so aussehen:
myGeomForm.position[0] := 3;
Es kann sinnvoll sein, mittels der "default"-Direktive eine Kurzform einzuführen und direkt über den Namen der Klasseninstanz auf eine Property zuzugreifen:
property position[index : Integer] : Integer read getPos write setPos; default;
myGeomForm[0] := 3;
Obiger Zugriff ist identisch mit dem Zugriff auf "position", da die Property "position" als Default-Property festgelegt wurde. Selbstverständlich kann es nur eine Default-Property pro Klasse geben!
Ich möchte an dieser Stelle eine besondere Art von Properties aufzeigen, nämlich die Ereignisse. Dabei möchte ich nur recht oberflächlich vorgehen, eine tiefergehende Beschreibung ist im Rahmen dieses Crashkurses nicht sinnvoll.
Ereignisse sind in der Programmierung unter Windows sehr wichtig, weil sie die beste Möglichkeit sind, auf die Eingaben des Nutzers zu reagieren. Ein Ereignis wird bespielsweise ausgelöst, wenn der Nutzer auf einen Button klickt: Das Ereignis "OnClick" des entsprechenden Buttons wird ausgelöst.
Nun könnte man in einer Klasse einfach eine Methode einbauen, welche ausgeführt wird, wenn ein Ereignis eintritt. Jedoch ist dies nicht wirklich praktikabel, weil dann bei jedem Button, auf den geklickt wird, immer dasselbe passieren würde, was natürlich Unsinn wäre. Man braucht also eine Methode, welche für jede Instanz unterschiedlich ist. Und genau das ist ein Ereignis: eine Property, welche eine Methode enthält!
Dabei ist genau festgelegt, wie eine Methode, die einem Ereignis zugewiesen wird, auszusehen hat. So muss die Methode, welche einem OnClick-Ereignis zugewiesen wird, eine Prozedur mit einem Parameter vom Typ TObject sein. Wird nun das Ereignis ausgelöst, wird die Methode ausgeführt, welche dem Ereignis zugewiesen wurde.
Das ist sich erst einmal merkwürdig anhören und soll daher am nachfolgenden Beispiel genauer erläutert werden. Erstellen Sie dazu eine neue Delphi-Anwendung und platzieren Sie einen Button auf der Form. Klicken Sie nun doppelt auf eine freie Stelle der Form. Sie sehen nun den Codeeditor vor sich, der Cursor blinkt in der Methode "FormCreate" der Form1: diese Methode wurde intern dem OnCreate-Ereignis von Form1 zugewiesen, wird also aufgerufen, wenn die Form erzeugt wird.
Fügen Sie unter der "FormCreate"-Methode eine neue Methode ein:
procedure TForm1.doSomething(Sender: TObject); begin ShowMessage('Foo'); end;
Die Methode sollte über dem "end." am Ende der Unit stehen, und muss natürlich noch im interface-Abschnitt deklariert werden, im public-Bereich von Form1.
Fügen Sie nun noch in die Methode "FormCreate" den folgenden Code ein:
Button1.OnClick := doSomething;
Starten Sie nun das Programm und klicken Sie den Button an. Wenn alles korrekt ist, wird Ihnen nun eine Nachrichtenbox mit dem Text "foo" entgegen springen. Das, was sonst Delphi intern für Sie erledigt, wenn Sie doppelt auf einen Button klicken (nämlich eine Methode für das OnClick-Ereignis anlegen und zuweisen), haben Sie nun manuell gemacht: Sie haben die Methode "doSomething" angelegt und bei Erstellen der Form dem OnClick-Ereignis des Buttons zugewiesen. Sie wird ausgeführt, wenn der Button geklickt wird.
Sie werden bemerken, dass die Methode "doSomething" einen Parameter "Sender : TObject" hat, der überhaupt nicht genutzt wird. Der Grund dafür ist die oben bereits erwähnte Vorschrift, wie ein Ereignis auszusehen hat. Ein Ereignis hat - wie jede andere Property - einen Typ, so ist z.B. ein OnClick-Ereignis vom Typ TNotifyEvent, welches wie folgt deklariert ist:
TNotifyEvent = procedure(Sender: TObject) of object;
Und wie Sie einer Property vom Typ "Integer" auch nur einen Integer zuweisen können, so können Sie einem TNotifyEvent auch nur ein TNotifyEvent zuweisen: Eine Prozedur mit einem Parameter vom Typ "TObject", welche an eine Klasse gebunden ist ("of object"), also eine Methode ist.
Im normalen Delphi-Betrieb ist es das einfachste, die IDE die entsprechenden Methoden anlegen zu lassen und den Ereignissen zuweisen zu lassen. Der Objektinspektor zeigt Ihnen zu jedem Objekt auf der Form auch die verfügbaren Ereignisse an: Objekt markieren, im Objektinspektor die Karteikarte "Ereignisse" wählen. Möchten Sie einem Ereignis eine Methode zuweisen, klicken Sie doppelt auf das leere Feld neben dem Namen des Ereignisses. Eine Methode wird angelegt und dem Ereignis zugewiesen. Bestehende Methoden können Sie einem Ereignis zuweisen, indem Sie nicht doppelt klicken, sondern mittels der DropDown-Liste eine bestehende Methode auswählen.
Mehr soll an dieser Stelle nicht zu Ereignissen gesagt werden, obiges sollte Sie in die Lage versetzen, einen Großteil der Aufgaben zu erledigen.
Es kann manchmal sinnvoll sein, dass man eine Methode nicht über die Instanz einer Klasse aufrufen möchte, sondern nur über die Klasse. So könnte man sich vorstellen, dass die Klasse "TgeomForm" eine Methode "dimension" besitzt, welche zurückgibt, welche Dimension die geometrischen Objekte besitzen, die durch diese Klasse dargestellt werden. Das Ergebnis dieser Methode wäre nicht abhängig von einer Instanz, sondern für die gesamte Klasse identisch.
Möchte man eine solche Methode haben, so leitet man sie bei der Deklaration mit dem Schlüsselwort "class" ein.
type TgeomForm = class {...} public class function dimension : Integer; end; {...} class function TgeomForm.dimension : Integer; begin result := 2; end;Selbstverständlich kann man in Klassenmehtoden nicht auf die Eigenschaften einer Klasse zuzugreifen, da diese nur existieren, wenn man mit Instanzen arbeitet!
Hier möchte ich noch einmal zusammentragen, was die Vorteile der OOP sind. Ich hoffe, sie haben das bereits selbst erkannt, aber es kann nichts schaden, Ihnen das alles noch einmal in Erinnerung zu rufen! ;-)
Dies sind insgesamt vier Punkte, die hier aufgezählt wurden. Die OOP bietet noch sehr viel mehr Vorteile, aber da die OOP hier nur sehr knapp beschrieben wurde, können auch nicht alle Vorteile hier aufgezählt werden. Ich möchte Sie bitten, sich mittels weiterer, auf OOP spezialisierter Tutorials und evtl. Bücher tiefer in das Thema einzuarbeiten, falls Sie Interesse daran haben. Zu empfehlen ist es allemal, OOP erleichert die Arbeit enorm!
Eine Exception (zu Deutsch "Ausnahme") tritt dann auf, wenn ein unerwarteter Fehler im Programm auftritt. Unerwartet heißt hierbei, dass z.B. nicht geprüft wurde, ob eine Variable Null ist und bei einer Divison durch diese Variable ein Fehler eintritt, nämlich die nicht definierte Division durch Null.
Eine solche Exception würde, wenn man nichts dagegen täte, dem Nutzer als Fehlermeldung entgegen springen und das ist etwas, das man auf jeden Fall vermeiden sollte. Nichts verunsichert einen Nutzer mehr. ;-) Das Prinzip von try-except und try-finally wird oft auch als "Structured Exception Handling" (SEH) bezeichnet.
Man vermeidet solche Ausnahmen, indem man sie behandelt, wenn sie auftreten. Bitte schalten Sie für das nachfolgende Beispiel die Option "Bei Delphi-Exceptions stoppen" unter "Tools -> Debugger-Optionen -> Sprach-Exceptions" aus. Ansonsten würden Sie als Programmierer auch behandelte (und für den Endnutzer abgewendete) Exceptions sehen.
var a, b: Integer; c : Double; begin a := 5; b := 0; c := a / b; ShowMessage(FloatToStr(c)); end;
Sobald Sie diesen Code ausführen, wird Ihnen die Meldung "Gleitkommadivision durch Null" entgegen springen. Eine solche Meldung sollte natürlich den Nutzer nie erreichen, sondern im Programm verarbeitet werden.
try c := a / b; except exit; end;
Die Syntax ist ganz einfach: Eingeleitet wird die so genannte "try-except-Anweisung" durch das Schlüsselwort "try". Dieses wird gefolgt von den Befehlen, welche ausgeführt werden sollen und dabei eventuell einen Fehler produzieren. Sie müssen übrigens nicht in "begin" und "end" verpackt werden.
Anschließend folgt das Schlüsselwort "except". An dieses Schlüsselwort schließt sich der Block von Befehlen an, der ausgeführt wird, sobald eine Exception auftritt, auch die "Ausnahmebehandlung" genannt. In einem richtigen Programm sollten hier Befehle stehen, welche den korrekten Ablauf des Programmes trotz des Fehlers garantieren. In diesem Fall wird die Prozedur einfach verlassen.
Es ist auch möglich, gezielt auf bestimmte Arten von Exceptions zu reagieren. Das geht so:
try c := a / b; except on EZeroDivide do c := 0; on EOverflow do c := 1000000; else exit; end;
Hier wird bei einer Division durch Null das Ergebnis auf Null gesetzt, bei einem Überlauf (also wenn die Zahlen für den Datentyp "double" zu groß werden), wird das Ergebnis auf eine Million gesetzt. Bei allen anderen Fehlern wird die Prozedur beendet.
Eine try-finally-Anweisung wird dann verwendet, wenn es Code gibt, der auf jeden Fall (also bei einem normalen Programmablauf und bei einer Exception) ausgeführt werden soll. Dies ist inbesondere dann der Fall, wenn man mit Objekten arbeitet, da diese freigegeben werden sollten, komme was da wolle. Daher nennt man eine try-finally-Anweisung der folgenden Art auch einen "Speicherschutzblock":
myStringList := TStringList.Create; try macheWas(myStringList); finally myStringList.Free; end;
Hier wird zuerst einmal eine Stringlist erstellt (zur Verwendung dieser bitte die Delphi-Hilfe bemühen). Im try-Abschnitt wird dann einiges damit gemacht. Und egal ob in diesem Teil ein Fehler auftritt oder nicht, muss der Speicher, welche die Stringliste belegt, auch wieder freigegeben werden. Dies wird im finally-Abschnitt erledigt.
Wichtig: Sie sollten bei der Arbeit mit Objekten immer an den Speicherschutzblock denken!
Hier möchte ich zum Schluss noch auf ein paar Dinge hinweisen, welche Sie im Laufe dieses Crahskurses sicherlich zumindest teilweise mitbekommen haben, auch wenn sie noch nicht explizit ausgeführt wurden. Es geht um den Kopf einer jeden Delphidatei. Dieser hat verschiedene Teile:
Eine Delphi-Unit ist in zwei Teile geteilt: "interface" und "implementation". Sie haben sicherlich bereits erraten, welche Bedeutung diese Teile haben: Im interace-Teil wird festgelegt, was alles in der Unit zu finden ist, der implementation-Teil stellt den eigentlich Inhalt der Unit dar.
Allerdings muss obige Aussage ein wenig präzisiert werden: Eine Unit kann mehr implementieren, als im interface-Teil enthalten ist, jedoch sind nur Dinge, die im interface-Teil vorkommen, in anderen Units sichtbar. So ist also eine Prozedur nur dann in anderen Units sichtbar, wenn sie auch im interface-Teil deklariert wurde.
Auch innerhalb einer Unit macht es einen Unterschied, ob eine Prozedur (oder auch Funktion) im interface-Teil deklariert wurde, oder nicht. Ist eine Prozedur nicht im interface-Teil deklariert, so kann man sie nur an einer Stelle aufrufen, welche unterhalb dieser Prozedur liegt.
procedure TForm1.FormCreate(Sender: TObject); begin foo; end; procedure foo; begin ShowMessage('foo'); end;
Dies produziert einen Fehler, wenn die Prozedur "foo" nicht im interface-Abschnitt deklariert wurde. Man kann sich das so vorstellen, dass der Delphi-Compiler beim Aufruf von "foo" noch gar nicht soweit gelesen hat, dass er diese Prozedur kennen könnte. Schreibt man die Prozedur "foo" über ihren Aufruf, so hat der Compiler sie bereits "gelesen" und der Aufruf glückt.
Alternativ deklariert man "foo" im interface-Abschnitt:
interface uses {...} type TForm1 = class(TForm) procedure FormCreate(Sender: TObject); {...} end; procedure foo; {...} implementation
Damit kennt der Compiler bereits den Namen der Prozedur "foo" und produziert keinen Fehler mehr. Jetzt wäre "foo" auch aus anderen Units heraus aufrufbar.
Es kann vorkommen, dass man doch einmal auf eine Prozedur oder Funktion zugreifen muss, welche im Quelltext erst später erfolgt und dass man die Reihenfolge nicht so ändern kann, dass dieses einfach möglich ist. Für solche Fälle kann man das so genannte "Fowarding" verwenden. Dabei gibt man dem Compiler an einer früheren Position den Namen einer Prozedur oder Funktion mit, welche erst später implementiert wird. Also so ähnlich wie ein interface-Teil, nur in der Implementation. ;-)
procedure foo; forward; procedure TForm1.FormCreate(Sender: TObject); begin foo; end; procedure foo; begin ShowMessage('foo'); end;
Nun würde - auch ohne Deklaration von "foo" im interface-Teil auch dieser Quelltext funktionieren, denn über der FormCreate-Methode wurde dem Compiler der Prozedur "foo" bekannt gegeben. Damit klar ist, dass nur der Name bekannt gegeben werden soll, die Prozedur aber noch nicht implementiert werden soll, schreibt man noch das Schlüsselwort "forward" dahinter.
Auch bei Klassen gibt es ab und an die Notwendigkeit des Forwardings, also das eine Klasse eine andere benötigt, die aber erst später eingeführt wird. Dies würde sich dann im interface-Teil abspielen. Die Lösung ist fast identisch mit der Lösung bei Prozeduren oder Funktionen. Im nachfolgenden Beispiel soll eine Klasse "TFotoalbum" mehre Fotos ("Array of TFoto") speichern, jedes Foto jedoch auch wissen, zu welchem Fotoalbum es gehört ("Fparent").
type TFoto = class; TFotoalbum = class(TObject) private Ffotos : Array of TFoto; end; TFoto = class(TObject) private Ffilename : String; Fparent : TFotoalbum; end;
Der einzige Unterschied (außer der Position im interface-Teil) zum Forwarding von Prozeduren und Funktionen besteht darin, dass das Schlüsselwort "foward" nicht verwendet wird. Stattdessen wird lediglich bekannt gegeben, dass es eine Klasse "TFoto" geben wird. Dies macht man mit der Anweisung "TFoto = class;", mehr darf dort auch nicht stehen, so zum Beispiel auch nicht, von welcher Klasse "TFoto" abgeleitet werden soll. Das wird erst angegeben, wenn die vollständige Deklaration erfolgt.
Damit eine Unit (z.B. "Unit1") den Inhalt einer anderen Unit (z.B. "Unit2") "kennt", muss man Unit2 in die uses-Klausel von Unit1 aufnehmen. Dadurch wird alles, was in Unit2 im interface-Abschnitt steht, Unit1 bekannt und kann verwendet werden. Wenn Sie sich die Unit ansehen, welche Unit für ein Formular anlegt, werden Sie sehen, dass schon einiges in der uses-Klausel drin steht. Dies sind Units, welche Delphi mitbringt und die für das Darstellen von Formular und Komponenten nötig sind.
Zusätzlich zu der standardmäßigen uses-Klausel im interface-Abschnitt kann man auch noch eine uses-Klauses im implementation-Abschnitt anlegen. Der Inhalt einer dort eingetragenen Unit ist dann nur im implementation-Teil bekannt, nicht aber im interface-Teil. Wozu ist das gut?
Dieses Vorgehen wird verwendet, um einen so genannten "überkreuzenden Bezug" zu verhindern. Ein überkreuzender Bezug entsteht dann, wenn man Unit2 in die uses-Klausel (interface-Bereich) von Unit1 schreibt, und Unit1 in die uses-Klausel (interface-Bereich) von Unit2. Das würde eine Endlosschleife ergeben, weil jede Unit die andere benutzt.
Passiert dies, kann man sich in vielen Fällen damit retten, dass man eine der beiden Einträge in der uses-Klausel im implementation-Abschnitt vornimmt. Denn die uses-Klausel im implementation-Abschnitt ist wie alles andere dort nur in dieser Unit bekannt, kann also auch keinen überkreuzenden Bezug erzeugen. Leider kann man dadurch die Inhalte der eingebundenen Unit auch nur im implementation-Abschnitt nutzen.
Eng mit dem Thema "interface-Abschnitt" verbunden ist das so genannte "überladen von Funktionen". Darunter versteht man, dass man verschiedene Funktionen mit gleichem Namen, aber unterschiedlichen Parametern hat. Hier zu nochmal das Beispiel der Rechteck-Klasse:
type TRechteck = class(TgeomForm) private Fhoehe : Integer; Fbreite : Integer; public constructor create(hoehe, breite : Integer); overload; constructor create(groesse : Integer); overload; end;
constructor TRechteck.create(hoehe, breite: Integer); begin inherited create; FHoehe := hoehe; FBreite := breite; end; {...} constructor TRechteck.create(groesse : Integer); begin inherited create; FHoehe := groesse; FBreite := groesse; end;
Diese Klasse besitzt nun zwei Konstruktoren: einmal der Konstruktor mit zwei Parametern, wie er bereits bekannt ist (er erzeugt ein Rechteck mit der gegebenen Höhe und Breite) und einmal einen Konstruktor mit nur einem Parameter, welcher ein Quadrat mit der gegebenen Kantenlänge erzeugt.
Damit Delphi weiß, dass man wirklich zwei Methoden gleichen Namens verwenden möchte, muss man bei der Deklaration das Schlüsselwort "overload" hinter jede dieser Methoden setzen. Wichtig ist, dass Delphi anhand der Anzahl und der Art der Parameter eindeutig bestimmen können muss, welche Methode gemeint ist! Ansonsten ist eine Überladung nicht möglich. In diesem Fall ist die Unterscheidung nicht schwer, sie erfolgt über die Anzahl der Parameter: Wird der Konstruktor mit einem Parameter aufgerufen, wird ein Quadrat erzeugt, bei zwei Parameter ein Rechteck.
Selbstverständlich funktioniert das Überladen auch mit Funktionen und Prozeduren und nicht nur mit Konstruktoren. Eine Überladung ist auch nicht auf Methoden (also an Objekte gebundene Funktionen und Prozeduren) beschränkt, sondern funktioniert auch bei nicht-objektgebundenen Funktionen bzw. Prozeduren. Die Deklaration ist dabei mit der Deklaration bei Methoden identisch, nur halt nicht das restliche Zeugs einer Klassendeklaration drum herum steht.